Table of contents
Open Table of contents
- Cutlass开发
- CuTe Layout 概念详解
- Coalesce 详解
- CuTe Layout Composition
- Complement补集
- A∘B 的输入输出分析
- Division
- Product
- Tensor
- Tensor algorithms
- CuTe MMA
sgemm- 矩阵乘法的两阶段执行:数据搬运与计算
local_tilelocal_partitionmake_tiled_copy和make_tiled_mma- 两者对比
sgemm_2.cu最简实现TiledMMA分区:A/B/C 的计算视图sgemm_sm70最简实现- 对于TiledCopy和ThrCopy,对于TiledMMA和ThrCopy
- CuTe TMA Tensor 深度解析
- 1. 发明背景:TMA 指令为什么需要新的 Tensor 类型
- 2. 第一步过渡:Tensor 的迭代器不一定是指针
- 3. 第二步过渡:从「生成整数」到「生成坐标」
- 4. 构造坐标迭代器:ArithmeticTuple 与 ArithmeticTupleIterator
- 5. 最核心的思想跃迁:Stride 不一定是整数
- 6. Basis Element:坐标空间中的单位基向量
- 7. 构造真正的 TMA Tensor:完整例子详解
- 8. 逐项解读那串「最吓人的打印」
- 9. 为什么 CuTe 原有工具链可以直接复用
- Swizzle 的基本工作原理
- 三个模板参数
<B, M, S>的严格定义与计算方法 - 明确的使用场景判断
- Tensor Core
mma硬件级空间切分与数据交织法则
Cutlass开发
前置知识:[[深度学习基础]]、[[cuda开发]]、[[GPU架构代际演进]]、[[GPU存储层级]]
行列基础概念
a[M][N] 这种写法,本质上就是 a[row][col],对应的坐标系就是 a[y][x]。
其次,行主序代表x方向连续,列主序代表y方向连续(存储连续)
| 维度名称 | 坐标变量 | 对应 GPU 索引 | 物理内存行为 | 步进 (Stride) |
|---|---|---|---|---|
| 行方向(水平方向) | x (Column) | blockIdx.x | 连续访问 (Coalesced) | 1 |
| 列方向(垂直方向) | y (Row) | blockIdx.y | 跳跃访问 | Width |
- 行方向是X方向,但要数出是哪一行,得靠 Y 坐标,而在代码中,变量基本都代表坐标而非方向!
注:行方向和行号不同,行方向是维度方向,而行号代表坐标,由idx.y表示
列方向和列号不同,列方向是维度方向,而列号代表坐标,由idx.x表示
- 列优先:方向向下优先遍历
block分工
在高性能计算(HPC)的矩阵乘法实现中,主流算子库(如 cuBLAS、CUTLASS)通常采用以结果矩阵C为导向的并行任务划分策略。
其核心逻辑是将目标矩阵 C 划分为一系列互不重叠的计算单元(Tile),并将每个线程块(Block)与一个特定的C-tile强绑定:
- 即每个 Block 的唯一任务是计算并输出其负责的 C 区域。在执行过程中,Block 扮演“需求方”的角色,根据其在 C 中的坐标索引,动态地从全局内存中迭代加载对应的 A 矩阵行切片与 B 矩阵列切片进行累加计算。这种设计通过将计算任务空间与输出内存空间对齐,最大限度地减少了写回冲突,并实现了负载均衡。
CuTe详解
layout
CuTe Layout 是 NVIDIA Cutlass 库的核心抽象,其本质是一个从多维逻辑坐标空间到一维线性内存偏移的映射函数。它巧妙地利用 C++ 模板递归与元编程技术,将复杂的嵌套张量结构通过“逐层降维”的方式,还原为基础的地址偏移。
一个典型的 Layout 由 Shape(形状) 和 Stride(步长) 两个核心部分组成:
- Shape: 定义了张量的逻辑结构与维度大小。
- Stride: 定义了逻辑下标在对应维度上移动一个单位时,在物理内存中产生的线性偏移量。
1. 核心计算原理:内积映射
Layout 的基本操作是将逻辑坐标向量 P 与步长向量 S 进行内积运算,从而计算出物理偏移量 Offset。
对于一个简单的二维 Layout:
-
Shape: $$ (d_0, d_1) $$
-
Stride: $$ (s_0, s_1) $$
任意坐标 (i, j) 的物理地址计算公式为: $$ Offset = i \cdot s_0 + j \cdot s_1 $$ 示例:
若 Layout 为 Shape: (2, 3),Stride: (3, 1),则逻辑坐标 (1, 2) 对应的偏移量为:
$$
1 \cdot 3 + 2 \cdot 1 = 5
$$
即该元素在内存中的实际地址为 &A + 5。
2. 高阶嵌套与递归降维
CuTe 的强大之处在于支持分级嵌套(Hierarchical Layouts)。对于经过多次映射或重塑的复杂 Layout,其 Shape 和 Stride 在结构上保持严格的一一对应(Congruent)。
复杂嵌套示例:
- Shape:
((2, (2, 2)), (2, (2, 2))) - Stride:
((1, (4, 16)), (2, (8, 32)))
在这种结构中,内积运算以递归方式展开。计算深层嵌套坐标的偏移时,CuTe 会逐层解析嵌套关系,直到触达最底层的标量步长。
3. Layout 的组合与退化
嵌套 Layout 并非孤立存在,它们可以通过**合并(Flattening)与归约(Reduction)**在不同逻辑视图间转换:
- 分级合并:上述嵌套 Shape
((2, (2, 2)), (2, (2, 2)))在逻辑上等价于((2, 4), (2, 4))。 - 维度压缩:进一步合并可视为
(8, 8)的二维平面,最终在总容量上退化为(64)的一维线性空间。 - 进制还原:这种映射关系类似于高维进制系统。通过 Stride 的指引,我们可以将一个一维线性索引(如第 35 个元素)反向推导出其在高维空间中的多级嵌套坐标。
在 CuTe Layout 的体系中,将一维线性索引(Logical Index)还原为多维分级嵌套坐标(Hierarchical Coordinate)的过程,本质上是一个基于基数(Radix)的递归解构过程。
Layout_Left 和 Layout_Right 两种情况下的读取优先级和内存跨步(Stride):
场景一:Layout_Left(类似于 Col-Major,列主序)
核心法则:从**最左侧、最内层(Left-most, Inner-most)**的元素开始,向右解析。最左侧的维度变化最快,内存连续。
对于 ((4, 8), (7, 2)),在 Layout_Left 的法则下,读取优先级的顺序是:先 4 -> 再 8 -> 再 7 -> 最后 2。
逐步推导 Stride 的过程:
- 最先读取 4 (Mode 0):它是最左侧的维度,因此它在内存中是连续的。
- Stride_0 = 1
- 接着读取 8 (Mode 1):每当“4”循环完一圈,才轮到“8”进一位。所以跨度是前面维度的总大小。
- Stride_1 = Stride_0 $\times$ 4 = 1 $\times$ 4 = 4
- 接着读取 7 (Mode 2):跨入右边的 Tuple 了。
- Stride_2 = Stride_1 $\times$ 8 = 4 $\times$ 8 = 32
- 最后读取 2 (Mode 3):变化最慢的维度。
- Stride_3 = Stride_2 $\times$ 7 = 32 $\times$ 7 = 224
结论:如果指定为 Layout_Left,CuTe 自动生成的布局等价于 Layout<Shape<<4, 8>, <7, 2>>, Stride<<1, 4>, <32, 224>>>。先读 4。
场景二:Layout_Right(类似于 Row-Major,行主序 / C 语言数组标准)
核心法则:从**最右侧、最内层(Right-most, Inner-most)**的元素开始,向左解析。最右侧的维度变化最快,内存连续。
对于 ((4, 8), (7, 2)),在 Layout_Right 的法则下,读取优先级的顺序被彻底反转:先 2 -> 再 7 -> 再 8 -> 最后 4。
逐步推导 Stride 的过程:
- 最先读取 2 (Mode 3):它是最右侧的维度,因此内存连续。
- Stride_3 = 1
- 接着读取 7 (Mode 2):
- Stride_2 = Stride_3 $\times$ 2 = 1 $\times$ 2 = 2
- 接着读取 8 (Mode 1):跨入左边的 Tuple 的最右侧。
- Stride_1 = Stride_2 $\times$ 7 = 2 $\times$ 7 = 14
- 最后读取 4 (Mode 0):变化最慢。
- Stride_0 = Stride_1 $\times$ 8 = 14 $\times$ 8 = 112
结论:如果指定为
Layout_Right,CuTe 自动生成的布局等价于Layout<Shape<<4, 8>, <7, 2>>, Stride<<112, 14>, <2, 1>>>。根本不是先读 4 或 8,而是先读 2!
- Stride_0 = Stride_1 $\times$ 8 = 14 $\times$ 8 = 112
结论:如果指定为
还原算法:递归解构(Recursive Deconstruction)
当一个线性索引 L 进入一个 Shape 为 (d_0, d_1, …, d_n) 的 Layout 时:
- 左侧优先取余:第 0 维坐标 $$ i_0 = L \pmod{d_0} $$ 这是因为在列主序中,最左边的维度变化最快。
- 步进整除:更新索引 $$ L’ = \lfloor L / d_0 \rfloor $$ 用于计算后续维度的坐标。
- 递归嵌套:如果 d_0 本身是一个嵌套Shape (s_0, s_1),则将 i_0 作为新的线性索引,重复上述步骤进入下一层括号内部。
实例推导:从线性索引到嵌套坐标
假设我们有一个嵌套 Shape:
$$ Shape: ((2, 4), 8) $$ 我们需要还原线性索引 L = 35 对应的嵌套坐标 $$ ((i_{0,0}, i_{0,1}), i_1) $$
第一层解构(最外层括号):
最外层视作二维结构: $$ d_{outer0} = (2,4) = 8(乘积),d_{outer1} = 8 $$
-
计算外层第 1 维: $$ i_1 = \lfloor 35 / 8 \rfloor = 4 $$
-
计算外层第 0 维的线性值: $$ L_{inner} = 35 \pmod 8 = 3 $$
第二层解构(进入内层括号 (2, 4)):
现在对 $$ L_{inner} = 3 $$ 在 Shape (2, 4) 中进行还原:
-
计算内层第 0 维 $$ i_{0,0} = 3 \pmod 2 = 1 $$
-
计算内层第 1 维: $$ i_{0,1} = \lfloor 3 / 2 \rfloor = 1 $$
最终结果:
线性索引 35 还原后的分级嵌套坐标为:((1, 1), 4)。
4. 维度增长的优先级
在 CuTe 中,维度增长的优先级(即谁变动得快)是从左到右的,但这种增长是嵌套发生的。这种“左到右”不仅存在于最外层的括号,也递归地存在于每一个子括号内部。
- 同级比较: 在任何一个括号对
(...)内部,左边的元素永远比右边的元素变动更快(步长更小)。 - 跨级比较: 一个括号整体被视为其父级的一个“大维度”。只有当左边括号内的所有可能性都穷尽了,右边的元素才会增加。
对于给出的坐标 A((1, (0, 1)), (0, (0, 1))): 我们可以将其视为 A(Row, Col),其中:
- Row =
(1, (0, 1)) - Col =
(0, (0, 1))
在这个层级,Row 整体变动最快。这意味着物理地址上,A(0, 0) 后面紧跟着的是 A(1, 0),而不是 A(0, 1)。
换个方式理解:在层次化布局中,坐标的嵌套遵循‘由外向内’的导航逻辑:右侧的分量决定了数据所在的宏观‘街区’(大块),而左侧的分量则在选定的街区内进行微观‘寻址’(细分单元)。
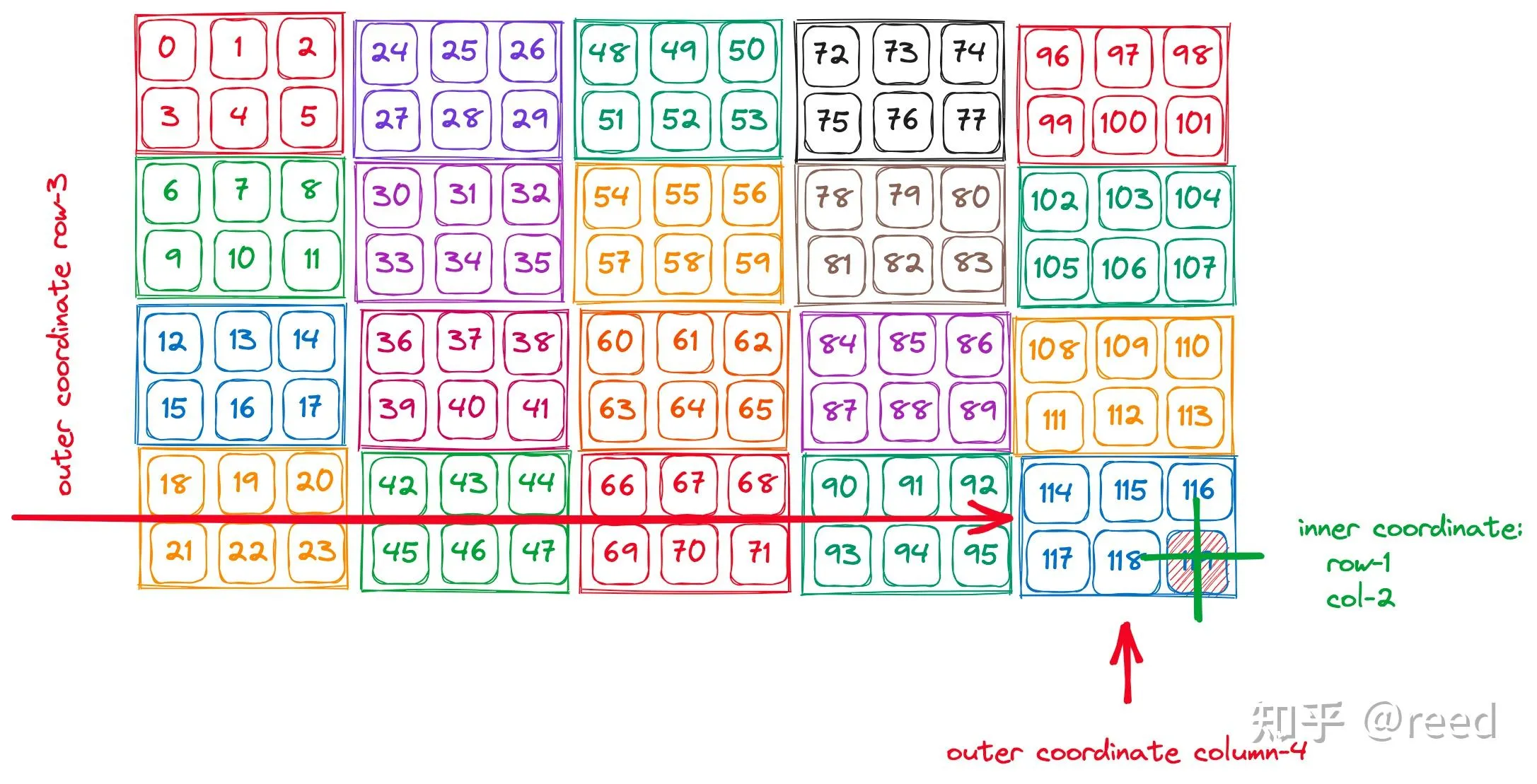
以上图为例,coord: ((1, 3), (2, 4))所表示的位置可以按这样的方式找到:首先提取坐标各维度的右侧分量组成宏观坐标 (3, 4),如同图中的红色标注,在全局范围内锁定对应的“大块”位置(即第 4 个块行与第 5 个块列的交汇处),随后进入该区块内部,利用左侧分量组成的细分坐标 (1, 2),如绿色标注所示,在局部格点中精准定位到具体的逻辑元素。
5. _的切片原则
取layout时,可以使用_来选择整个维度,并结合数字来取出自己想要的layout:
可以把 _ 直接理解成“这一维我不把它钉死,而是要把它整条保留下来”:其中_,代表固定维度,通常代表结果的维度。数字表示选定维度,有几个数字通常代表结果少了几维;
-
如果没有
_,说明所有维度都被数字完全确定了,结果就是一个具体的数; -
有一个
_,说明还留着一个方向可以变化,所以结果是一条线,也就是一维向量; -
有两个
_,说明还留着两个方向可以变化,所以结果就是一个面,也就是二维矩阵。
核心本质就一句话:数字负责定位,_ 负责保留;_ 不是随便写的符号,而是在说“这一维不要取单点,要取完整视图”,所以看一个切片表达式,不用先管它多复杂,只要先数有几个 _,就能立刻知道最后拿到的是“点、线,还是面”。通过切片,可以一次性将需要的数据全部取出,如可以固定thread,将thread需要用的数据全部取出,不需要复杂的映射关系计算

6. layout的查看逻辑
看一个 layout 本质上就是看“下标每增加一步,物理地址会跳到哪里”。如果默认按二维来看,想看某一列里有哪些元素,就把列固定住,让行的各层下标按顺序变化,然后用 stride 算出它们相对起点的偏移;想看某一行也是同理,只不过换成固定行、让列变化。
在Layout<Shape <Shape <_2,_2,_2>,Shape <_2,_2,_2>>,
Stride<Stride <_1,_16,_4>,Stride<_8,_2,_32>>>下
比如你想看 Row 内部是怎么跳的,固定列为 0: $$ Row(0,0,0) \to 偏移 0\ Row(1,0,0) \to 偏移 1(Stride 1)\ Row(0,1,0) \to 偏移 16(Stride 16)\ Row(0,0,1) \to 偏移 4(Stride 4)\ $$
结论: 在行方向上,它是先走 1 步,再跳 4 步,最后猛跳 16 步。
说明虽然逻辑上都只是“行坐标在变”,但物理地址并不是老老实实连续增长,而是会按 stride 规则跳到不同位置;如果列不是 0,再额外加上这一列本身带来的固定偏移就行。所以不管是二维变二维,还是一维拆成多维,本质都一样:逻辑坐标的递增是平滑的(0, 1, 2, 3…),但地址的跳跃是由 Stride 决定的
一般来说,对于实际的开发,可以将layout统一作为二维理解,任何 layout 都看成:行维度 × 列维度,这两个维度可以是单层stride,也可以是嵌套的跳跃
CuTe Layout 概念详解
一、Layout 兼容性(Compatibility)
什么叫”兼容”?
两个 Shape 兼容,需要满足两个条件:
- size 相等
- A 的所有坐标都是 B 的合法坐标
直觉上:A 能”放进” B 里。
24 compatible with (4,6) ✅ 因为 4×6=24,且0~23都是(4,6)的合法坐标
24 compatible with ((2,2),(3,2)) ✅ 因为 2×2×3×2=24
(4,6) NOT compatible with 24 ❌ 虽然size相等,但(4,6)的坐标是2D的,24只接受1D坐标💡 关键:兼容是单向的。A 兼容 B,不代表 B 兼容 A。这就像”正方形是矩形,但矩形不是正方形”。
二、Layout 接受多种坐标
这是最重要的概念。一个 Layout 同时接受多种坐标系:
以 Shape (3,(2,3)) 为例,size = 3×2×3 = 18,它同时接受三种坐标:
| 1-D坐标 | 2-D坐标 | 自然坐标(Natural) |
|---|---|---|
| 0 | (0,0) | (0,(0,0)) |
| 1 | (1,0) | (1,(0,0)) |
| 3 | (0,1) | (0,(1,0)) |
| 6 | (0,2) | (0,(0,1)) |
| 16 | (1,5) | (1,(1,2)) |
同一行的三个坐标完全等价,映射到同一个内存偏移。
为什么要有这么多坐标系?
- 用1D坐标 → 当作 18 个元素的数组
- 用2D坐标 → 当作 3×6 的矩阵
- 用自然坐标 → 当作 3×(2×3) 的张量
同一块内存,按需解读,零开销!
三、坐标映射:怎么从任意坐标到自然坐标?
规则:列主序(colex order),从右往左数进位(和我们日常从左往右的”字典序”相反)。
以 Shape (3,(2,3)) 举例,用2D坐标 (row, col) 遍历,col 先变:
col=0 col=1 col=2 col=3 col=4 col=5
(0,0) (1,0) (2,0) (0,1) (1,1) (2,1) ...
0 1 2 3 4 5 ... ← 1D坐标1D 坐标 6 → 2D 坐标 (0,2) → 自然坐标 (0,(0,1))
四、Index 映射:从自然坐标到内存偏移
就是内积:自然坐标 × Stride,各分量相乘后求和。
以 (3,(2,3)):(3,(12,1)) 为例:
自然坐标 (i,(j,k)) → 偏移 = i*3 + j*12 + k*1
五、Layout 操作速查
Sublayout(取子布局)
Layout a = (4,(3,6)):(1,(4,12))
layout<0>(a) → 4:1 // 取第0个mode
layout<1>(a) → (3,6):(4,12) // 取第1个mode(还是个tuple)
layout<1,0>(a) → 3:4 // 取第1个mode的第0个子modeselect vs take
// select:按索引挑选,可以不连续
select<1,3>(a) // 取第1和第3个mode
// take:取连续范围 [begin, end)
take<1,3>(a) // 取第1、第2个modegroup & flatten(分组与展平)
Layout a = (2,3,5,7):(1,2,6,30)
group<0,2>(a) → ((2,3),5,7):((1,2),6,30) // 把mode 0~1 打包成一个嵌套mode
flatten(...) → (2,3,5,7):(1,2,6,30) // 展平回去用处:把矩阵重新解读成向量,或把向量重新解读成矩阵,不移动数据。
Coalesce 详解
考虑两个相邻的 mode:s0:d0 和 s1:d1
规则1:s0:d0 ++ _1:d1 => s0:d0
size=1 的 mode 无论 stride 是多少,坐标永远是0,贡献永远是 0 * d1 = 0。直接丢掉。
_3:_5 ++ _1:_99 => _3:_5规则2:_1:d0 ++ s1:d1 => s1:d1
同上,前面那个 size=1 的也丢掉。
规则3:s0:d0 ++ s1:(s0*d0) => s0*s1:d0
当后一个 mode 的 stride = 前一个 mode 的 size × stride 时,可以合并。
直觉:这说明两个 mode 在内存里是连续排列的,就像列主序矩阵。
_2:_1 ++ _4:_2 => _8:_1验证:s0=2, d0=1, s1=4, d1=2,s0*d0 = 2*1 = 2 = d1 ✅,合并为 8:1
规则4:没法合并,保持原样
_2:_1 ++ _4:_3 => (_2,_4):(_1,_3)例子
Layout<Shape<_2, Shape<_1, _6>>,
Stride<_1, Stride<_6, _2>>>先展平(flatten)成一系列相邻的 mode:
_2:_1, _1:_6, _6:_2第一步:_2:_1 ++ _1:_6 → 规则1:后面 size=1,丢掉 _1:_6 → 剩下 _2:_1
第二步:_2:_1 ++ _6:_2 → 检查规则3:s0*d0 = 2*1 = 2 = d1 → 合并为 _12:_1
结果:_12:_1
By-mode Coalesce(保持维度)
有时候我们需要保持 Layout 的维数。比如我有个2D layout,希望结果还是2D。
auto a = Layout<Shape<_2, Shape<_1,_6>>,
Stride<_1, Stride<_6,_2>>>{};
coalesce(a, Step<_1,_1>{}) // 结果是 (_2,_6):(_1,_2)Step<_1,_1> 的意思是:“把这个 layout 当成2D的,分别对每个维度做 coalesce”
- 第0维:
layout<0>(a)=_2:_1→ coalesce →_2:_1 - 第1维:
layout<1>(a)=(_1,_6):(_6,_2)→ coalesce →- 展平:
_1:_6, _6:_2 _1:_6size=1,丢掉- 剩
_6:_2 - 结果:
_6:_2
- 展平:
最终合并两维:(_2,_6):(_1,_2)
Coalesce = 把一个复杂的 Layout 化简成最少 mode 数、等价的简单 Layout。就像化简分数一样,值不变,形式更简单,计算更高效。
CuTe Layout Composition
核心思想
还记得我们说过 Layout 是整数到整数的函数吗?有了这个视角,Composition 就很自然:
R = A ∘ B,即 R(c) = A(B(c))就是普通的函数复合。复合的结果还是一个 Layout,即:A,B为layout,A∘B输入为两个layout,Composition输出也为一个layout,不过该layout复合了AB的layout,隐去了A 的逻辑坐标,使得新layout输入B 的逻辑坐标可以直接得到物理地址
A ∘ B 就是 “让 B 当坐标生成器,让 A 当地址计算器”
结果是一个能直接映射真实内存地址的新 Layout(也就是得到 B 能直接映射真实地址的 layout)
而由于 stride 恒正,B 的逻辑坐标从 0 开始单调递增,对应到 A 里的物理地址也是从小到大走,所以
A∘B,B取值越小,取出的永远是 A 物理地址偏移越小的tile,而不是中间某块或末尾某块,故一般需要和A∘(B, B*)结合使用,详见下文
怎么计算 Composition?
关键性质:左分配律
A ∘ (B₀, B₁, ...) = (A ∘ B₀, A ∘ B₁, ...)所以可以把 B 拆成各个 sublayout,分别和 A 复合,最后拼起来。
这样问题化简为:A(多模)和 s:d(单个整数mode)怎么复合?
计算 A ∘ s:d 的两步走:A 是多维的时候
A = (6,2):(8,2)现在要算 A ∘ 4:3,即从 A 中每隔3步取,共取4个:
R(0) = A(0) = 0
R(1) = A(3) = 24
R(2) = A(6) = 2
R(3) = A(9) = 26问题来了:这4个结果能写成一个 Layout 吗?怎么找到它的 shape 和 stride?
Step 1:除法 /——“每隔 d 步”
(6,2) / 3 的含义是:把步长3从整个 shape 里”除出去”,从左往右逐维处理。
过程:
- 第0维 size=6,3 ≤ 6,且 6 能被 3 整除 ✅
- 直接在第0维除掉:6 ÷ 3 = 2
- 3 已经被完全消耗,不需要动第1维
(6,2) / 3 = (2,2)对比几个例子感受规律
(6,2) / 2 → 第0维 6÷2=3,消耗完 → (3,2)
(6,2) / 3 → 第0维 6÷3=2,消耗完 → (2,2)
(6,2) / 6 → 第0维 6÷6=1,消耗完 → (1,2)
(6,2) / 12 → 第0维 6÷6=1,还剩2,第1维 2÷2=1 → (1,1)当 d > 第0维的 size 时,才会”溢出”到第1维。
stride 怎么变?
除法只影响被消耗到的那一维的 stride,规则是乘以”残余的 d”。
(6,2):(8,2) / 3:
d=3 全部被第0维消耗(6÷3=2)
第0维 stride × 3 = 8×3 = 24
第1维不动
→ (2,2):(24,2)
(6,2):(8,2) / 12:
d=12,第0维 size=6,先消耗6,剩余 d=12÷6=2
第0维 stride × 6 = 8×6 = 48,shape变为1
剩余 d=2 进入第1维,2÷2=1
第1维 stride × 2 = 2×2 = 4,shape变为1
→ (1,1):(48,4)Step 2:取模 %——“共取 s 个”
Step 1 告诉我们”每隔3步的无限序列长什么样”,但我们只要前4个。
(2,2):(24,2) % 4 的含义:从这个无限序列里截取前4个元素。
shape (2,2) 总共有 2×2=4 个元素,恰好等于 s=4,所以直接保留:
(2,2):(24,2) % 4 = (2,2):(24,2)更直接地说:
(6,2) % 3 = (3,1) → 只需要3个,第0维取3,第1维取1
(6,2) % 6 = (6,1) → 只需要6个,第0维取满6,第1维取1
(6,2) % 12 = (6,2) → 需要12个,全取规律:s 先填满第0维,填满了再溢出到第1维。
Composition 的实际用途
用途1:把1D layout 重塑成矩阵
20:2 ∘ (5,4):(4,1)“把连续步长为2的20个元素,重新解读成5×4的行主序矩阵”
= (20:2 ∘ 5:4, 20:2 ∘ 4:1)
= (5:8, 4:2) ← 都是trivial情况:s:d ∘ s':d' = s':(d*d')
= (5,4):(8,2)结果:第一维步长8,第二维步长2,正是行主序5×4矩阵的访问模式。
用途2:By-mode Composition(按维度复合)
用 Tiler 分别对每个维度施加不同的 sublayout:
// a 是一个 (12,(4,8)):(59,(13,1)) 的layout
auto tiler = make_tile(Layout<_3,_4>{}, // 对第0维:3:4
Layout<_8,_2>{}); // 对第1维:8:2
auto result = composition(a, tiler);
// 等价于:
make_layout(composition(layout<0>(a), 3:4),
composition(layout<1>(a), 8:2));含义:从 a 的第0维中每隔4步取3个,从第1维中每隔2步取8个,得到一个 3×8 的子块。
用途3:Shape 作为 Tiler(stride=1 的特殊情况)
auto tiler = make_shape(Int<3>{}, Int<8>{});
// 等价于 make_tile(3:1, 8:1)
// 含义:取第0维前3个,取第1维前8个(连续子块)Composition = “用 B 描述的访问模式去索引 A”,结果是一个新 Layout,直接表达了这种复合访问。 这是 CuTe 里 tiling、partitioning 等所有高级操作的基础。
Complement补集
Complement 的核心目的:
- A* 把整个空间按照 A 的大小为单位等分 每个 A* 的取值 = 第 n 个 A 的起始偏移
- 所以A*实际上是以一个A的大小为最小单位的,如果想要将所有的元素一一对应,需要用(A, A*)组合,这也是为什么 A* 存在的意义——A 只能取开头,A* 负责把这个开头平移到第 n 块的起始位置,两者配合才能访问到任意位置的 tile
Complement 到底做什么?
Layout complement(Layout A, Shape cotarget)- 输入:布局 A(已经选走的元素)和一个目标大小 cotarget(通常就是原来数据的总大小)
- 输出:一个新布局 R(剩下的元素)
3 个铁律(post-conditions):
- R 的大小不会超过 cotarget(不会越界)
- R 的 stride 是递增的、正的 → 结果唯一
- R 和 A 完全没有重叠(不踩到已经选走的元素)
例子
例1:
A = 4:1(连续 4 个元素)
cotarget = 24(总共 24 个元素)
→ complement = 6:4
意思:把 A 重复 6 次,每次间隔 4,就把 24 个位置全覆盖了!
例2:
A = 6:4(每 4 个跳一个)
cotarget = 24
→ complement = 4:1
把 A 的“空洞”正好用连续 4 个填满。
例3:
A = (4,6):(1,4)(标准的 4×6 矩阵)
cotarget = 24
→ complement = 1:0(啥都不用加,已经满了)
例4:
A = (2,2):(1,6)
cotarget = 24
→ complement = (3,2):(2,12)

- 灰色格子 = A 选走的元素
- 其他颜色 = complement 自动补上的“重复块”
- 最终 codomain 刚好是 24,而且每个位置只出现一次
A∘B 的输入输出分析
在学习 product 和 Division 之前,我们需要对复合映射 A∘B 的定义域与值域建立更严谨的理解。
基本结构
A∘B 本质上是一个复合函数 A(B(input)),既然是函数,自然具有对应的定义域与值域:
- 单值性:理想情况下,A 与 B 均被构造为单值函数——即定义域与值域之间一一对应,这样能保证不重复取值,但是layout也可以构造为取重复值的函数。
- 值域:由最外层函数 A 的映射决定,其输出范围即为物理地址的范围。
- 定义域:A 和 B 各自都是单值函数,但 B 的值域作为 A 的输入,两者的范围未必对齐,所以B的输入可能会导致A产生越界。
Layout的注意点
CuTe Layout Algebra是纯粹的代数操作,像是composition,B 的输出直接作为 A 的输入按 stride 继续计算,没有任何隐式的边界检查或取模处理:
$$
A(B(\text{input}))
$$
这里有一点需要特别注意:所有的 layout 都不会对输入做任何合法性检查。 CuTe 的 layout 计算本质上就是一个纯粹的数学公式:
$$
index = \sum (coord_d \times stride_d)
$$
无论是 composition 还是单独的 layout,当你输入一个超出其定义域的值时,它不会报错,而是会代入公式继续按照 stride 规律计算并返回一个结果——只不过这个结果是一个越界的非法物理地址。这种行为贯穿所有 layout 操作,其后果只有在运行时通过 cuda-memcheck 才能捕获,可能表现为 Shared Memory 越界访问或非法内存地址错误。因此,保证输入合法性完全由使用者自己负责,因此每次取用数据,最好用size()检查定义域,cosize()检查最大允许物理地址。
根据 B 的值域与 A 的定义域的大小关系,存在三种情况:
B 的值域小于 A 的定义域 遍历 B 的所有输出,无法覆盖 A 的完整定义域,A 的部分物理地址永远不会被访问到。
B 的值域等于 A 的定义域 B 的输出与 A 的定义域恰好一一对应,整个复合函数是严格的单值函数,每个物理地址被访问恰好一次,是最理想的状态。
B 的值域大于 A 的定义域 B 的输出超出 A 的定义域范围后,A 继续代入公式计算,产生越界的非法物理地址。
结合 A* 来看
对于 A*∘B∘C∘... 这条复合链,A* 始终作为最后一层翻译器,将任意输入转换为以 A-tile 为单位的起始偏移。无论前面经过多少层复合,只要最终输出经过 A*,结果永远是合法的 tile 起始偏移,A* 对前面整条复合链完全透明。
而这条复合链能否不重不漏地覆盖所有坐标,唯一的约束条件就是整条链是否构成单值函数,等价于链上每一步都没有发生遗漏或越界。
因此 (A, A*∘B∘C∘...) 的本质可以归纳为:A 负责 tile 内部的寻址,后面这条复合链无论有多长多复杂,只要保持单值函数的性质,就能精确覆盖所有 tile 的起始偏移。两者组合后即可不重不漏地访问整个空间。
换句话说:形如 (A, A*∘B∘C∘...) 的 layout,只要满足两个条件:其一,A*∘B∘C∘... 整条复合链是单值函数;其二,最终输出经过 A* 的翻译。那么这个 layout 就能保证 tile 内的每一个元素都被不重不漏地映射到对应的物理地址,并方便地通过下标访问。
这一分析是理解后续 product 和Division规则的基础
Division
Division到底想解决什么问题?
对于一个tile布局,divide目的就是切片,最终得到一个layout,我们可以通过这个layout,用简单的下标形式获取每个tile里每个值的真实物理地址,而且对于这个tile,我想要在这个tile上面进行新的layout布局,也可以通过divide继续获得直达的物理地址映射,如此一直下去
所以 logical_divide(A, B) 的结果,应该同时包含:
- tile 内部的布局
- tile 之间的布局
公式(divide到底干了什么)
$$ A \oslash B := A \circ (B, B^*) $$
第一步:A ∘ B是什么
$$ A \circ B $$ 就是:
在大布局
A上,取出由B描述的 tile,就是 composition,准确来说,A ∘ B 就是 “让 B 当坐标生成器,让 A 当地址计算器”
结果是一个能直接映射真实内存地址的新 Layout(也就是得到 B 能直接映射真实地址的 layout)
第二步:B*
B* 是 B 的 complement,它的作用是标记”第几个 tile”,也就是将A分成若干个B,每个 B* 取值对应一个 stride 偏移,表示当前 tile 相对于第一个 tile 的起始位置偏移量。
第三步:(B, B*)
把这两个拼起来: $$ (B, B^*) $$ 就是一个两层结构,结合stride:
- 第一层:tile 内部取值,如何跳跃取值
- 第二层:第几个tile
然后再喂给 A:
$$
A \circ (B, B^)=(A \circ B,A \circ B^)
$$
这就是 divide,他借助了A的中转,可以直接通过下标获取各个tile(由B*确定)里各个值(由B确定)的直达物理地址,最后的结果是二维的,准确的说是2-mode,第一个mode管一个tile内部的取值,第二个mode管不同tile的首地址位置
为什么用A∘(B,B*)而不是A∘B?
由 Complement 的定义可以知道,
A∘B只建立了一个 tile 和 A 之间的映射关系,它自然无法覆盖 A 的所有元素。而(B, B*)配合使用则能将 A 完整切分,由于(B, B*)的size和A相等,所以映射函数满足一一对应关系,由此可以用”第 n 个 tile 中第 m 个元素”的方式不重不漏地索引到每一个元素。因此,A∘(B, B*)才是真正完整的映射关系,它让 A 的每个物理地址都有对应的逻辑坐标可以访问到。
实现
template <class LShape, class LStride,
class TShape, class TStride>
auto logical_divide(Layout<LShape,LStride> const& layout,
Layout<TShape,TStride> const& tiler)
{
return composition(layout, make_layout(tiler, complement(tiler, size(layout))));
}logical_divide相当于把上述的三步一起做了,得到的直接是tile对于物理地址的layout
例子: $$ A = (4,2,3):(2,1,8) $$
$$ tiler B = 4:2 $$
$$ B^* = (2,3):(1,8) $$ 得到: $$ (B, B^) = (4,(2,3)):(2,(1,8)) $$ $$ A \circ (B, B^) $$
结果:
$$
((2,2),(2,3)):((4,1),(2,8))
$$
**为什么tile内部的排列形式变了:**由于做了Composition,相当于直接跳过了A取真实地址,所以((2,2)):(4,1),由于A本身就是对物理地址的真实排列做了加工的,而原来的 tile是按照A的逻辑坐标来顺序取值的,所以真实的地址当然会和原来的不同,相当于把A的加工也给还原回去了。 尽管底层物理排列发生了变化,但在编程接口层,CuTe 依然维持了逻辑上的易用性。开发者仍可沿用 (4, (2,3)) 这种直观方式进行取值,系统会自动将线性索引 4 解构为对应的多维坐标 (2,2),从而在享受物理寻址效率的同时,屏蔽了底层的地址转换细节
对于 2D 布局 A:
$$
A = (9,(4,8)):(59,(13,1))
$$
如果按一个 2D 的 tiler 去切:
$$
B = <3:3,\ (2,4):(1,8)>
$$
这里的意思是:
- 在列方向上,按照
3:3拿 - 在行方向上,按照
(2,4):(1,8)拿
按照上面同样的三步,得到 2D divide 的结果:
- M 方向:
(TileM, RestM) - N 方向:
(TileN, RestN)
其中Rest项更多的是表示当前是第几个tile,合起来就是: $$ ((TileM,RestM), (TileN,RestN)) $$ 这其实很“规整”,因为它保留了原来矩阵的 M / N 语义。
所以 logical_divide 的优点之一就是:
虽然它切了 tile,但它没有把原来的维度语义打乱。
M 还是 M,N 还是 N。 只是每个维度内部被拆成“tile 内部”和“tile 外部”。
对于不同的函数,改变的只是结果的表示形式
对于logical_divide结果是:
$$
((TileM,RestM), (TileN,RestN))
$$
对于zipped_divide结果是:
$$
((TileM,TileN), (RestM,RestN))
$$
也就是:
- 把 tile 内部的各个维度,收拢到一起
- 把 tile 外部的编号维度,也收拢到一起
变成:
- mode-0:一个完整 tile
- mode-1:tile 的编号空间
对于tiled_divide结果是:
$$
((TileM,TileN), RestM, RestN, …)
$$
适合你想单独保留每个 tile 维度编号的时候。
对于flat_divide结果是:
$$
(TileM, TileN, RestM, RestN, …)
$$
适合某些需要最简单 rank 结构的场景。
Layout Shape : (M, N, L, ...)
Tiler Shape : <TileM, TileN>
logical_divide : ((TileM,RestM), (TileN,RestN), L, ...)
zipped_divide : ((TileM,TileN), (RestM,RestN,L,...))
tiled_divide : ((TileM,TileN), RestM, RestN, L, ...)
flat_divide : (TileM, TileN, RestM, RestN, L, ...)- 请特别注意:当前 Layout 的顶层 Shape 是
(M, N, L, ...)时,如果你对它做zipped_divide,而 Tiler 的顶层 Shape 是<TileM, TileN>,那么zipped_divide会按 by-mode 规则只处理前两个顶层 modeM, N,而把后面的L, ...原样并入 rest,结果就是
((TileM,TileN), (RestM,RestN,L,...))Product
基本概念回顾
在理解乘积之前,先回顾几个关键概念:
- Layout:一个从整数到整数的映射函数,由 Shape(形状)和 Stride(步长)定义
- cosize(A):Layout A 所映射到的值域大小(即
max(A) + 1) - complement(A, M):在大小 M 的空间内,A 的”补集布局”,描述 A 未覆盖的元素
- composition(A, B):布局的组合,即
A ∘ B,先用 B 索引再用 A 映射
逻辑乘积(logical_product)的定义
数学定义
logical_product(A, B) 的结果同样是一个二模(2-mode)布局,定义为:
$$
A \otimes B := (A, A^* \circ B)
$$
其中:
-
模式 0(Mode 0):就是布局 A 本身(tile 本身)
-
模式 1(Mode 1):找不同tile的首地址位置 $$ A^* \circ B $$
C++ 实现
template <class LShape, class LStride,
class TShape, class TStride>
auto logical_product(Layout<LShape,LStride> const& layout,
Layout<TShape,TStride> const& tiler)
{
return make_layout(
layout,
composition(complement(layout, size(layout) * cosize(tiler)), tiler)
);
}Product的本质与A*范围
为了便于理解,我们将 layout 记为 A,tiler 记为 B,那么complement操作的 cotarget 就是 size(A) * cosize(B)。
先理解 A* 的职责
A* ∘ B 的含义是:按照 B 规定的顺序,依次取出每个 A-tile 在内存中的首地址偏移。换句话说,取多少个 tile、按什么顺序取,完全由 B 说了算。
因此 A* 必须考虑最坏的情况——当 B 索引到它值域中最大的那个 tile 编号 n 时,A* 也要能正确响应。即便 B 并不会把 [0, n] 范围内的每一个 tile 都取到(中间可能有”跳过”的情况),A* 仍然必须按照最大可能的需求来预留空间,而不能心存侥幸。
再理解 product 的本质
product(A, B) 并不是在一块已经固定好的内存里重新分配现有的元素,而是:以 A 的排布样式为模板,根据 B 所需的副本数量和顺序,构造出多份互不重叠的 A 的复制体。
这些复制体会优先”填入” A 原本布局中未被实际占用的空洞(即 A 内部因步长等原因留下的间隙),空洞填满之后,再向后开辟新的连续空间。
本质上,product 是在定义一套新的 layout 映射关系,而不是搬动或重新分配底层数据。
最终结论
size(A):一个 tile 包含的元素个数;cosize(B):B 在最坏情况下需要寻址的最大 tile 数量。
两者相乘,得到的正是:一个足以容纳这些复制体、并且尽量利用空洞的 codomain 目标范围——既充分利用了 A 内部的空洞,又保证了在最坏情况下不会越界。
一维示例详解
基本示例:A = (2,2):(4,1),B = 6:1
A 的含义:
- Shape
(2,2),Stride(4,1) - 共 4 个元素,映射到的物理下标为:
{0, 1, 4, 5} size(A) = 4,cosize(A) = 6
B 的含义:
- Shape
6,Stride1 - 表示”把 A 重复 6 次”,且按顺序排列
计算过程:
第一步:求补集
complement(A=(2,2):(4,1), N=6×4=24)
→ A* = (2,3):(2,8)A* 表示在 24 个元素的空间中,A 重复出现的起始偏移布局:
- 第一维
2:2→ 同一 tile 内两个 “组” 的起始偏移(0, 2) - 第二维
3:8→ 三组 tile 的起始偏移(0, 8, 16)
第二步:组合
composition(A*=(2,3):(2,8), B=6:1)
→ (2,3):(2,8)因为 B=6:1 是连续的 6 个,而 A* 已经恰好描述了 6 个 tile(2×3=6),所以结果不变。
第三步:拼接
logical_product(A, B) = ((2,2),(2,3)):((4,1),(2,8))结果是一个 rank-2 布局:
- Mode 0
(2,2):(4,1)→ tile 内的元素访问 - Mode 1
(2,3):(2,8)→ tile 之间的跳转
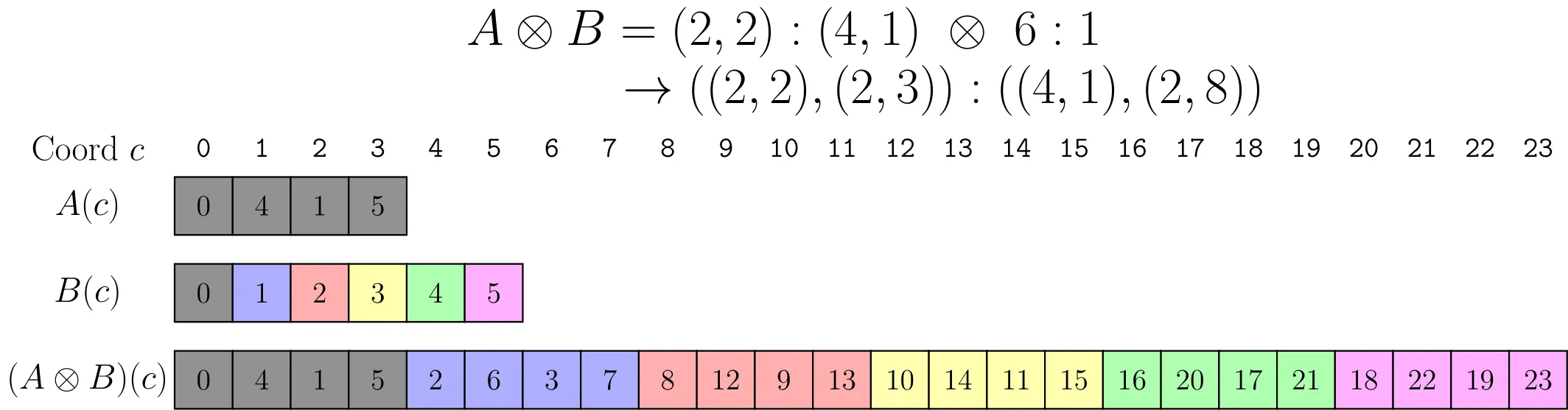
改变 tile 排列顺序:B = (4,2):(2,1)
logical_product(A=(2,2):(4,1), B=(4,2):(2,1))- B 共有 4×2=8 个 tile,且排列顺序按步长
(2,1)交织 - 结果变为 8 个 tile,每个 tile 内部结构与 A 相同,但 tile 之间的排列顺序由 B 决定
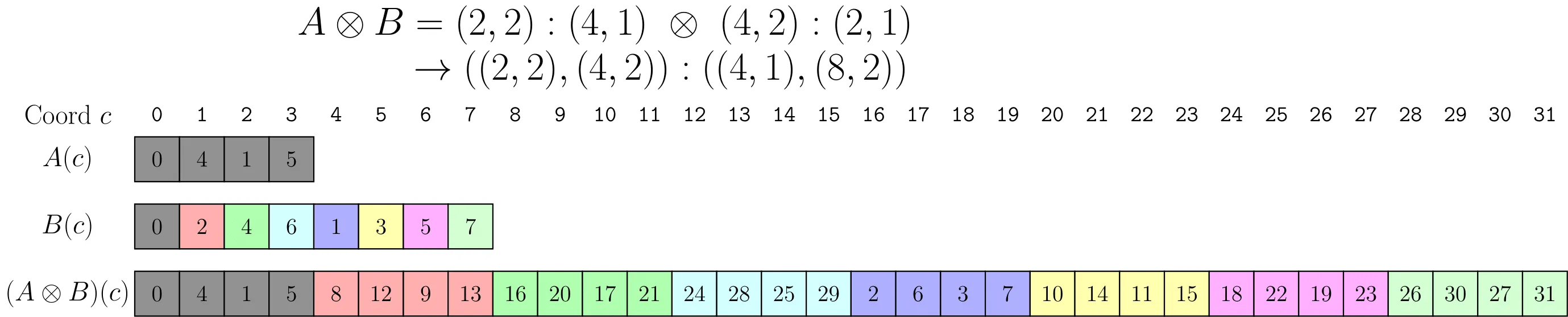
二维乘积与 rank-sensitive 变换
朴素方式的问题
直接用 logical_product 对二维 Layout 操作时,A 的行列放一起,R =A* ∘ B的行列也放一起,形如:
$$
((A_r,A_c),(R_r,R_c))
$$
但我们更想要行维度放一起,列维度放一起,因此就有了下面的不同product:
blocked_product(块状乘积)
$$ ((A_r,R_r),(A_c,R_c)) $$
先走 tile 内部,再走 tile 编号,所以 tile 会保持成“块”
blocked_product 还会自动对 Mode 0 进行 coalesce(合并),进一步简化布局。

raked_product(耙状/交织乘积)
$$ ((R_r,A_r),(R_c,A_c)) $$
先走 tile 网格,再走 tile 内部,所以 tile 会被打散成交错分布

zipped_product / tiled_product / flat_product
这三种变体是在 logical_product 的基础上对输出模式进行重排,以满足不同的使用场景:
Layout Shape : (M, N, L, ...)
Tiler Shape : <TileM, TileN>
logical_product : ((M,TileM), (N,TileN), L, ...)
zipped_product : ((M,N), (TileM,TileN,L,...))
tiled_product : ((M,N), TileM, TileN, L, ...)
flat_product : (M, N, TileM, TileN, L, ...)| 变体 | 适用场景 |
|---|---|
logical_product | 基础操作,需要手动处理模式 |
zipped_product | 需要明确区分”tile 内”和”tile 间”两个视角 |
tiled_product | 常见的分块迭代场景,tile 间维度保持独立 |
flat_product | 需要完全线性化的简单情形 |
下面我把这份 CuTe Tensor 教程重新写一遍,不按原文硬翻,而是按“为什么需要它 → 它到底是什么 → 怎么创建 → 怎么访问 → 怎么切片 → 怎么分块 → 为什么 GEMM 里离不开它”这条真正适合学习的主线来讲。核心依据是 CuTe 的 Tensor、Layout 和 Layout Algebra 文档。
Tensor
Tensor= 数据来源 + 索引规则
更准确地说:
Tensor=Engine+Layout
其中:
Layout负责:逻辑坐标 → 偏移Engine负责:偏移加到哪、怎么取数据,相当于一个迭代器
这样一来,算法就不用关心底层存储细节了。你写的仍然是“我要访问 (m,n)”,至于它是在 gmem、smem、寄存器,还是某种特殊迭代器上生成出来的数据,Tensor 帮你统一掉。
Tensor 不是“存数据的多维数组”这么简单。 它本质上是一个“用 Layout 解释数据”的视图/容器。
Tensor 和 Layout 的关系
Layout是纯映射函数Tensor是映射函数 + 数据载体
因此你可以把 Tensor 看成:“带数据的 Layout”
Engine
Engine 可以理解成一个对“迭代器/数组/指针”的轻量包装。
它最核心提供的是:
using iterator
using value_type
using reference
iterator begin()也就是说,Engine 本质上只需要能告诉 Tensor:
- 数据元素类型是什么
- 从哪开始
- 如何按偏移访问
通常用户不用手写 Engine,你直接 make_tensor(...),CuTe 会自动帮你构造合适的 engine。常见的有:
ArrayEngine<T,N>:像数组一样自己拥有数据ViewEngine<Iter>:像 view 一样只是看外部数据ConstViewEngine<Iter>:只读 view
所以,Engine 的职责不是搞复杂抽象,它只是帮 Tensor 统一“数据入口”。
Tensor 怎么创建
这里分成两大类:
- nonowning:不拥有数据,只是看现有数据
- owning:自己拥有数据,像一个小数组
Nonowning Tensor
最常见的形式就是:
Tensor A = make_tensor(ptr, layout);
Tensor A = make_tensor(make_gmem_ptr(A), layout);
Tensor A = make_tensor(make_smem_ptr(s), layout);意思是:
用
ptr指向的数据,再配上layout这套解释规则,构造一个 Tensor 视图。
其中CuTe 提供:
make_gmem_ptr(A):告诉系统这是 global memory 指针make_smem_ptr(s):告诉系统这是 shared memory 指针
一维 view
float* A = ...;
Tensor tensor_8 = make_tensor(A, make_layout(Int<8>{}));带 stride 的一维 view
Tensor tensor_8d2 = make_tensor(A, 8, 2);二维 global memory Tensor
Tensor gmem_8sx16d = make_tensor(make_gmem_ptr(A),
make_shape(Int<8>{},16));//默认 LayoutLeftshared memory Tensor
Layout smem_layout = make_layout(make_shape(Int<4>{},Int<8>{}));
__shared__ float smem[decltype(cosize(smem_layout))::value];
Tensor smem_4x8_col = make_tensor(make_smem_ptr(smem), smem_layout);这个例子里最该注意的是:
decltype(cosize(smem_layout))::valuecosize 是 CuTe 的函数,计算一个 Layout 的 codomain 大小,也就是这个 Layout 实际需要占用多少内存空间
关键点:cosize 返回的不是普通的 int,而是一个类型!因为 shape 和 stride 都是静态的(Int<4>, Int<8>),所以 CuTe 在编译期就能算出结果,返回一个 Int<32> 类型的对象,decltype 是 C++ 关键字,用来在编译期提取一个表达式的类型,而不实际执行它,因此:
decltype(cosize(smem_layout)) // → Int<32>(返回值的类型)最后通过::value取出值:
decltype(cosize(smem_layout))::value
// ↓ ↓ ↓
// 拿到类型 Int<32> 取出32
__shared__ float smem[decltype(cosize(smem_layout))::value];//定义shared memory大小Owning Tensor:自己拥有数据
如何创建:
Tensor rmem = make_tensor<float>(Shape<_4,_8>{});make_tensor_like
Tensor rmem_4x8_like = make_tensor_like(rmem_4x8_pad);make_tensor_like读取步长顺序,然后创建一个紧凑的、相同顺序的新 Tensor(shape 相同,顺序相同,stride长短可能不同)make_tensor_like可以传入Nonowning 型或Owning 型,但永远创建Owning 型,因为它的语义就是”给我一块寄存器,形状跟这个一样”
Owning 和 Nonowning 的本质区别
// make_tensor:传入了已有指针 → 非拥有型(视图)
make_tensor(ptr, layout) // ptr 是已有内存,我只是看它
// make_tensor<T>:没有指针,自己分配 → 拥有型
make_tensor<float>(shape) // 自己创建内存因此,Owning 创建大多数用于寄存器创建,他会自动销毁并回收内存
Tensor 访问元素
Tensor A = make_tensor<float>(
Shape<Shape<_4,_5>, Int<13>>{},
Stride<Stride<_12,_1>, _64>{});
Tensor B = make_tensor(b_ptr, make_shape(13,20));这个 A 的 shape 是:
((4,5), 13)意味着它第一大 mode 里又嵌了两个子 mode。 所以你既可以写:
A[make_coord(make_coord(m0,m1), n)]也可以写:
A(m,n)前者是自然层级坐标,后者是兼容坐标。
Tensor tiling
很多 Layout 的分块运算也能直接用在 Tensor 上:
composition(Tensor, Tiler)
logical_divide(Tensor, Tiler)
zipped_divide(Tensor, Tiler)
tiled_divide(Tensor, Tiler)
flat_divide(Tensor, Tiler)但是Layout 可以做 product,Tensor 不行。
因为 product 可能把 codomain 扩得更大,导致访问跑到原来 Tensor 有效边界之外,造成内存越界
切片_(Slicing)
切片(Slicing)和普通访问的核心区别在于:普通访问 A(coord) 返回一个元素,而切片 A(_, 5) 返回一个子 Tensor(视图)。触发切片的关键不是用没用 operator(),而是你有没有传入 _。
_ 可以直接理解成”这一维我不把它钉死,而是要把它整条保留下来”,类似 Matlab/Fortran 里的 :。数字表示固定坐标,_ 表示保留的维度:
- 没有
_:所有维度都被数字完全确定,结果是一个具体的数; - 有一个
_:还留着一个方向可以变化,结果是一条线(一维向量); - 有两个
_:还留着两个方向可以变化,结果是一个面(二维矩阵)。
切片本质上同时做两件事:
切片不是单纯”少看几维”,而是同时修改了起始指针和布局(Layout):
- 算出新 Tensor 的起点:把固定坐标(数字部分)喂给原 Layout,得到一个偏移量,加到原 iterator 上,新 Tensor 的数据起点就指向原 Tensor 中对应切片起始位置的地址;
- 构造新 Tensor 的 Layout:把传了
_的那些 mode 对应的 Layout mode 重新拼成一个新 Layout。
所以切片返回的不是”拷贝后的数组”,而是一个 view:新 Tensor = 新起点 + 新布局。
结果的 rank 取决于你在哪个层级写 _:
这是最容易出错的地方。_ 保留的是你当前写出来的那个层级的 mode,而不是简单地”保留几个数字”。切片不仅关心”留了什么元素”,还关心”以哪个层级把这些元素留下来的”。
以 shape 为 ((3,2), (2,5,2)) 的 Tensor A 为例:
| 写法 | 含义 | 结果 shape | 说明 |
|---|---|---|---|
A(2, _) | 第一大 mode 固定为 2,第二大 mode 整体保留 | (2,5,2) | 保留完整的第二大 mode |
A(_, 5) | 第一大 mode 整体保留,第二大 mode 固定坐标 5 | ((3,2)) | 第一大 mode 作为整体的 1 个 mode 被保留 |
A(make_coord(_,_), 5) | 第一大 mode 的两个子 mode 分别保留,第二大 mode 固定坐标 5 | (3,2) | 内部两个子 mode 被展开为 2 个独立 mode |
A(_, 5) 和 A(make_coord(_,_), 5) 包含的元素完全相同,但 rank 和 shape 不同——前者 rank 为 1,后者 rank 为 2。因此,结果 Tensor 的 rank,等于切片坐标中 _ 的个数(更准确地说,是当前层级保留了几个 mode,结果就有几个对应的 mode)。
核心本质就一句话:数字负责定位,_ 负责保留。
看一个切片表达式,不用先管它多复杂,只要先数有几个 _,就能立刻知道最后拿到的是点、线还是面。通过切片,可以一次性将所需数据全部取出——例如固定 thread 坐标,将该 thread 需要用的数据整块取出,完全不需要复杂的映射关系计算,这也是 local_tile、local_partition、TiledMMA 等高层抽象的底层基础。
Partition:本质上是“先divide,再切片”
Inner partition:
Tensor A = make_tensor(ptr, make_shape(8,24)); // (8,24)
auto tiler = Shape<_4,_8>{}; // (4,8)
Tensor tiled_a = zipped_divide(A, tiler); // ((_4,_8),(2,3))这个结果是典型的divide操作:
((_4,_8),(2,3))意思是:
- 第一个 mode:tile 本身,大小
4x8 - 第二个 mode:这些 tile 怎么排,排成
2x3,总共6个tile
如果某个 CTA 想拿其中一个 tile,比如 (blockIdx.x, blockIdx.y) 对应那个 tile,就写:
Tensor cta_a = tiled_a(make_coord(_,_), make_coord(blockIdx.x, blockIdx.y));也就是:
**每个 CTA 负责一整块数据。**如果掌握了divide操作,应该不难理解
Outer partition:取出每个tile相同位置的元素
还是同一个 tiled_a:
Tensor thr_a = tiled_a(threadIdx.x, make_coord(_,_)); // (2,3)这次操作完全反过来了:
- 第一个 mode(tile 内部)固定成
threadIdx.x - 第二个 mode(所有 tile 的排布)保留
所以 thr_a 的 shape 是 (2,3),因为它遍历的是所有 tile。
Thread-Value partition:通过线程选值
普通 partition 的思路是:
- 先按几何形状切 tile
- 再让线程从 tile 里拿自己的那部分
但有时候线程拿数据的方式根本不是简单矩形。 比如 MMA 指令规定:
- 哪些线程拿哪些 A 元素
- 哪些线程拿哪些 B 元素
- 哪些线程负责哪些 C fragment
这个分配模式常常非常“奇怪”,不是简单地“thread 0 拿第一行”。
这时 CuTe 用的是:
先构造一个 TV-layout:
(thread, value) -> 数据坐标
例如:
auto tv_layout = Layout<...>{}; // (T,V) -> (M,N)
Tensor A = make_tensor<float>(Shape<_4,_8>{}, LayoutRight{});
Tensor tv = composition(A, tv_layout); // (8,4)
Tensor v = tv(threadIdx.x, _); // 每个线程拿 4 个值第一步:你先定义一个“线程-值分配表”
tv_layout 规定:
- 8 个线程
- 每个线程 4 个值
- 这 32 个
(thread,value)对应原始4x8数据里的哪些坐标
第二步:以这张表为输入,来取相应值
tv = composition(A, tv_layout)使用A∘B ,把原来按
(m,n)看的数据,变成按(thread,value)来看。
第三步:每个线程切出自己那一行
v = tv(threadIdx.x, _)于是这个线程直接拿到“我该处理的那几个值”。
所以 TV partition 的本质是:
先显式描述“线程和数据的对应关系”,再让 Tensor 自动给你每个线程的局部视图。
TV Layout具体例子
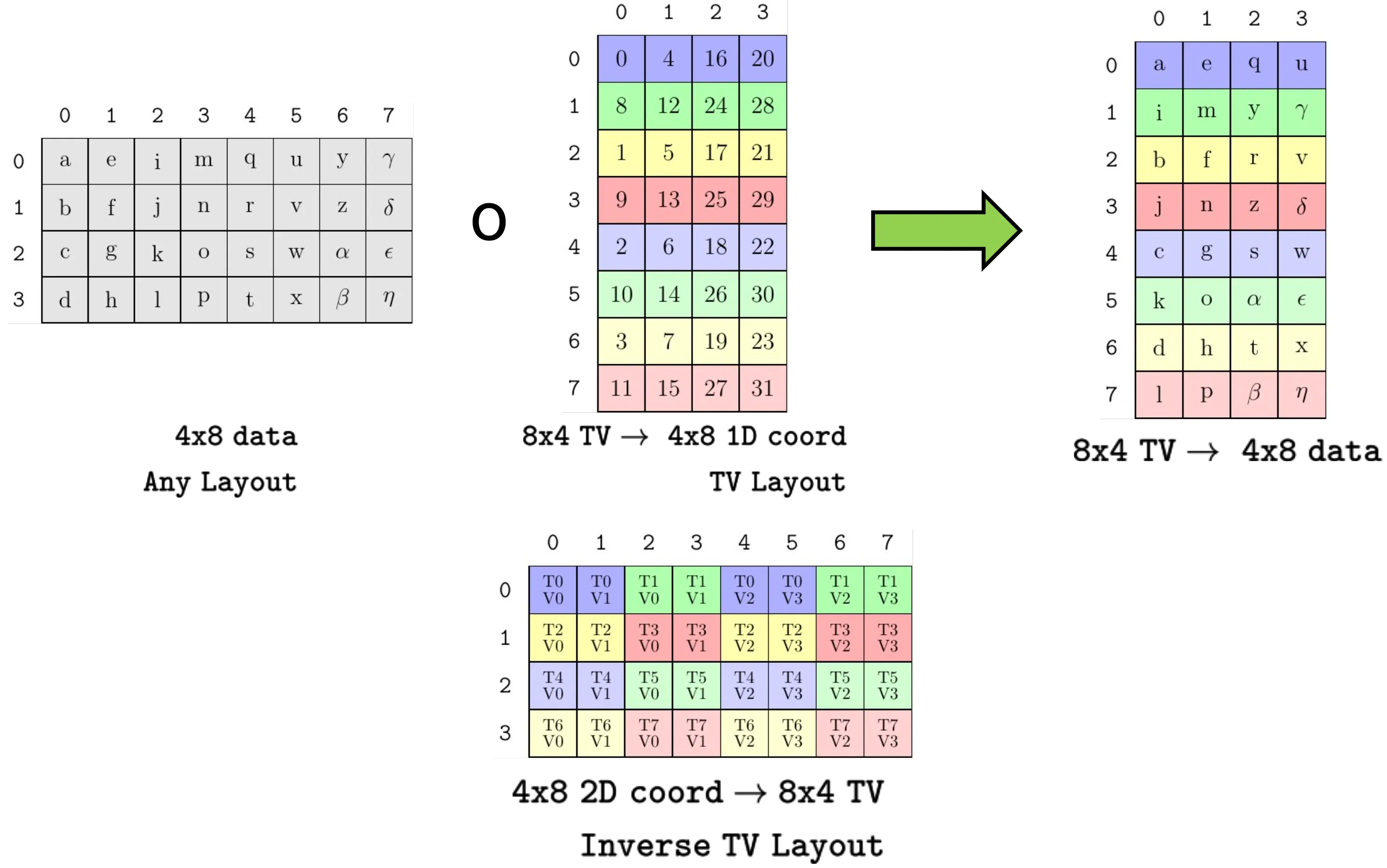
对于TV Layout,对于了解其作用很有必要,因此,单开一节,用例子讲透:
以SM80_8x8x4_F64F64F64F64_TN为例:
对于SM80_8x8x4_F64F64F64F64_TN的布局要求,画出相应的布局要求如下(更多的布局信息详见[[MMA不同架构数据排布]]):
![[SM80_8x8x4_F64F64F64F64_TN.png]]
其在Cute中对应的源码定义如下(include/cute/atom/mma_traits_sm80.hpp):
// (T32,V1) -> (M8,N8)
using SM80_8x4 = Layout<Shape<Shape<_4, _8>, _1>, Stride<Stride<_8, _1>, _0>>;
// (T32,V2) -> (M8,N8)
using SM80_8x8_Row = Layout<Shape<Shape<_4, _8>, _2>, Stride<Stride<_16, _1>, _8>>;
template <>
struct MMA_Traits<SM80_8x8x4_F64F64F64F64_TN>
{
using ValTypeD = double;
using ValTypeA = double;
using ValTypeB = double;
using ValTypeC = double;
using Shape_MNK = Shape<_8, _8, _4>;
using ThrID = Layout<_32>;
using ALayout = SM80_8x4;
using BLayout = SM80_8x4;
using CLayout = SM80_8x8_Row;
};在写 TVLayout 之前,你必须先在大脑中建立一个坐标系转换的概念。TVLayout 本质上是一个降维映射函数。它的作用是:
- 输入端 (Domain): 二维坐标 $(T, V)$。其中 $T$ 是线程的 ID(0~31),$V$ 是该线程持有的寄存器槽位/迭代索引(如 0, 1)。
- 输出端 (Codomain): 一维的逻辑平铺索引 (1D Logical Index),在不考虑 swizzle 和 padding 等额外操作的情况下,这个一维索引实际上就是真实数据在内存中的存放情况,也就是 $(T, V)$ 需要读取的数据对应的真实物理偏移。当做了额外操作,可以将输出理解为逻辑索引,将其与额外操作的 layout 相叠加,同样能得到真实索引。
底层逻辑前提(极度重要): 无论是 A、B 还是 C 矩阵,在 CuTe 的逻辑视角里,它们首先是一个多维张量(比如 C 是 $8 \times 8$),然后默认按照列主序(Column-Major)展平为一维空间。TVLayout 就是要算出:任意一个 $(T, V)$ 组合,在这个展平后的一维空间里,到底排在第几个位置?
第一阶段:正向映射(解析 SM80_8x4 与 SM80_8x8_Row)
就像之前说的,在 CuTe 中,所有的 TVLayout 都是一个将 $(T, V)$ 坐标映射为 一维内存偏移量 (1D Offset) 的函数。结合矩阵的主序(Majorness),这个 1D Offset 就能还原回逻辑坐标 $(Row, Col)$。
对于 Warp 级别的 MMA,线程总数固定为 32。所以线程坐标 $T$ 永远在 $[0, 31]$ 之间。
设 $T$ 的一维 ID 拆解后为 $(t_0, t_1)$,其代数关系固定为:
- $t_0 = T \pmod 4$ (变化快的内层)
- $t_1 = \lfloor T / 4 \rfloor$ (变化慢的外层)
| 模式 | A 矩阵要求 | B 矩阵要求 | PTX 后缀 |
|---|---|---|---|
| NT | M-major (列主序) | N-major (行主序) | .col.row |
| TN | K-major (行主序) | K-major (列主序) | .row.col |
| NN | M-major | K-major | .col.col |
| TT | K-major | N-major | .row.row |
| N向下连续,T向右连续 |
1. A / B 矩阵的 Layout (SM80_8x4)
代码定义:
// (T32,V1) -> (M8,N8) <-- 注:此处的注释 N8 有误导性,实际用于 A 是 8x4,用于 B 是 4x8
using SM80_8x4 = Layout<Shape<Shape<_4, _8>, _1>,
Stride<Stride<_8, _1>, _0>>;输入:$(t_0, t_1)$ 以及 $V=0$(因为 _1 代表只有一个值)。
一维偏移公式:$Offset = t_0 \times 8 + t_1 \times 1 + V \times 0 = t_0 \times 8 + t_1$。
【应用到 Matrix A(左下角)】
- 物理属性与连续性解析 (T 属性):A 矩阵的逻辑形状是 $M \times K$ 即 $8 \times 4$。由特征名
TN中的T(Transpose) 可知:- 之前(默认物理定义):如果是普通的列主序矩阵,连续的维度是 $M$ 维(垂直方向)。
- 现在(指令强制要求):加上
T属性后,底层硬件强制要求沿着 $K$ 维(水平列方向)必须是物理连续的。这种沿着 $K$ 维连续的特性,在物理行为上等同于行主序 (Row-Major)。但在 CuTe 的TVLayout原生一维解析域中,为了套用标准代数模型,它是把这个 $8 \times 4$ 空间作为一个基准的 列主序 (Column-Major) 来反向推导 Offset 坐标系的。
- 解码方程:在 $8 \times 4$ 标准列主序的逻辑空间中,$Offset = Row + Col \times 8$。
- 联立等式:$Row + Col \times 8 = t_1 + t_0 \times 8$。
- 推导坐标:
- $Row = t_1 = \lfloor T / 4 \rfloor$
- $Col = t_0 = T \pmod 4$
- (注:你看,相邻线程 $T_0 \dots T_3$ 对应的 $Col$ 维 ($K$ 维) 依次是 $0, 1, 2, 3$,完美满足了
T属性要求相邻线程沿着 $K$ 维连续读取的要求!)
【应用到 Matrix B(右上角)】
-
物理属性与连续性解析 (N 属性):B 矩阵的逻辑形状是 $K \times N$ 即 $4 \times 8$。由特征名
TN中的N(Non-Transpose) 可知:- 之前(默认物理定义):B 矩阵默认就是非转置的,要求沿着 $K$ 维(此时是行方向向下)是物理连续的,也就是标准的列主序。
- 现在(CuTe 底层代数复用魔法):虽然物理上 B 需要 $K$ 维连续(列主序),但 CuTe 为了让 B 复用和 A 完全一样的
SM80_8x4布局模板,在底层代数推导时,将 $4 \times 8$ 的 B 强行代入了一个 $8 \times 4$ 的视口。当我们把这个魔法结果映射回 $4 \times 8$ 的图片表象时,其 Offset 的增长规律表现成了 行主序 (Row-Major)。
-
解码方程:在 $4 \times 8$ 被反转视角的行主序等效矩阵中,$Offset = Col + Row \times 8$。
-
联立等式:$Col + Row \times 8 = t_1 + t_0 \times 8$。
-
推导坐标:
- $Row = t_0 = T \pmod 4$
- $Col = t_1 = \lfloor T / 4 \rfloor$
- (注:同样地,相邻线程 $T_0 \dots T_3$ 对应的 $Row$ 维 ($K$ 维) 依次是 $0, 1, 2, 3$,完美满足了
N属性要求相邻线程沿着 $K$ 维连续读取的要求!)
2. C 矩阵的 Layout (SM80_8x8_Row)
代码定义:
using SM80_8x8_Row = Layout<Shape<Shape<_4, _8>, _2>,
Stride<Stride<_16, _1>, _8>>;输入:$(t_0, t_1)$ 以及 $V \in [0, 1]$(因为是 _2,每个线程负责两个值)。
一维偏移公式:$Offset = t_0 \times 16 + t_1 \times 1 + V \times 8$。
为了方便寻找规律,我们提取公因数 8:$Offset = (2 \times t_0 + V) \times 8 + t_1$。
【应用到 Matrix C(右下角)】
- 物理属性:C 矩阵是 $M \times N$ 即 $8 \times 8$,且后缀明确写了是 行主序 (Row-Major),即沿着右侧的 $N$ 维是连续的。
- 解码方程:在 $8 \times 8$ 行主序矩阵中,$Offset = Col + Row \times 8$。
- 联立等式:$Col + Row \times 8 = t_1 + (2 \times t_0 + V) \times 8$。
- 推导坐标:
- $Row = 2 \times t_0 + V$
- $Col = t_1 = \lfloor T / 4 \rfloor$
第二阶段:如何看着图片手写 TV Layout
假设你现在只有右上角的 B 矩阵图片,你要如何从零写出 SM80_8x4?
Step 1: 确定矩阵维度和期望的连续性 (主序)
看右上角的 B 矩阵图:它有 4 行,8 列($4 \times 8$)。
结合我们上面讲的逻辑,虽然它承担着 $K$ 维连续的重任,但从这张 $4 \times 8$ 的图片表象来看,数据的一维 Offset 增长方向是横向的。我们据此得出,用于逆推的目标一维索引公式等效于 行主序 (Row-Major):$Offset = Col + Row \times 8$。
Step 2: 从图片中提取 $(Row, Col)$ 与 $T$ 的代数关系
我们观察图片中的数字规律:
- 找 Col 的规律:看第 0 列是 0, 1, 2, 3(T0-T3);第 1 列是 4, 5, 6, 7(T4-T7)。 得出结论:每隔 4 个线程换一列。因此 $Col = \lfloor T / 4 \rfloor = t_1$。
- 找 Row 的规律:看第 0 行是 0, 4, 8, 12;第 1 行是 1, 5, 9, 13。 得出结论:同一列中,相邻行的线程 ID 递增 1。因为每 4 个一循环,所以 $Row = T \pmod 4 = t_0$。
Step 3: 将关系代入目标一维索引公式
将 $Row = t_0$ 和 $Col = t_1$ 代入 Step 1 的公式:$Offset = t_1 + t_0 \times 8$
为了对应 CuTe 要求的输入格式,我们按 $(t_0, t_1)$ 的顺序重写等式:$Offset = t_0 \times 8 + t_1 \times 1$
Step 4: 提取 Stride,写出代码
在 CuTe 的标准模板 Shape<Shape<_4, _8>, _V> 中
- $t_0$ 的跨度 (Stride) 是 8。
- $t_1$ 的跨度 (Stride) 是 1。
- 因为图中每个线程只占一个格子,所以 $V=1$,Stride 为 0。
组合起来得到代码:
Layout<Shape<Shape<_4, _8>, _1>, Stride<Stride<_8, _1>, _0>>
这与官方源码分毫不差。
第三阶段:实例验证
为了确保理论 100% 成立,我们用代码推导的坐标去图片里“查字典”,如果严丝合缝,逻辑就无懈可击。 验证 1:Matrix A 中的 T23
- 公式推导:$T=23$。计算 $t_0 = 23 \pmod 4 = 3$,$t_1 = \lfloor 23 / 4 \rfloor = 5$。 根据前面推导的 A 矩阵 (Col-Major 解析视口) 坐标:$Row = t_1 = 5$,$Col = t_0 = 3$。
- 图片查验:请看左下角的 A 矩阵图。从上往下数第 5 行,从左往右数第 3 列(注意索引从 0 开始)。那个格子里的数字是不是 23?完全一致。(第 5 行依次是 20, 21, 22, 23)。 验证 2:Matrix B 中的 T18
- 公式推导:$T=18$。计算 $t_0 = 18 \pmod 4 = 2$,$t_1 = \lfloor 18 / 4 \rfloor = 4$。 根据前面推导的 B 矩阵 (Row-Major 等效视口) 坐标:$Row = t_0 = 2$,$Col = t_1 = 4$。
- 图片查验:请看右上角的 B 矩阵图。找到 Row 2(2, 6, 10, 14, 18, 22, 26, 30)。它的 Col 4 正好是 18。完全一致。
验证 3:Matrix C 中的 T5 (包含寄存器 V 切片)
- 公式推导:$T=5$。计算 $t_0 = 5 \pmod 4 = 1$,$t_1 = \lfloor 5 / 4 \rfloor = 1$。 根据前面推导的 C 矩阵 (Row-Major) 坐标:$Col = t_1 = 1$,$Row = 2 \times t_0 + V = 2 + V$。 当 $V=0$ 时,$Row = 2$;当 $V=1$ 时,$Row = 3$。
- 图片查验:请看右下角的 C 矩阵图。找到 Col 1。 Col 1 的排布从上到下是:4, 4, 5, 5, 6, 6, 7, 7。 可以看到,数字 5 占据了该列的第 2 行和第 3 行。这完美对应了我们的计算结果(V=0 放 Row 2,V=1 放 Row 3)。
CuTe partition 机制的底层架构与执行流解析
在 CuTe 的编程模型中,partition 并非单纯的数据结构拆分,而是一次基于代数复合与降维的编译期坐标变换。其核心逻辑可以拆解为以下四个递进的阶段:
1. 逻辑映射层的确立 (TVLayout / TVCLayout)
首先,我们需要定义线程与逻辑数据之间的映射关系。
-
输入侧 (
TVLayout): 接收当前线程 ID ($T$) 与寄存器槽位/迭代索引 ($V$),映射出该线程需要读取的数据在 $(M, N, K)$ 逻辑视角的坐标。 -
输出侧 (
TVCLayout): 同理,它定义了当前线程完成计算后,其负责的结果数据在输出矩阵逻辑排布中的 $(M, N, K)$ 位置。
2. 物理排布与代数复合 (Layout Composition)
底层内存(如 Shared Memory 或 Global Memory)本身拥有其基础的物理排布规则(即输入的底层 Layout),这里面包含了复杂的错位(Swizzle)防冲突机制或跨步(Stride)规则。这些规则都是以 $(M, N, K)$ 逻辑坐标作为输入的。
由于 TVLayout 的输出正好是逻辑坐标,因此可以直接将其作为算子,叠加(Compose)在底层物理 Layout 之上。这就形成了一个高阶的复合映射函数:直接从 $(T, V)$ 穿透到真实的物理内存地址。
3. 线程切片与静态降维 (Partition / Slicing)
这是发生质变的一步。当我们调用 partition 时,实际上是将当前执行的线程 ID(如 threadIdx.x)作为常量,硬编码代入到上述的复合函数中。
这一步在数学上称为切片(Slicing)或取陪集(Coset),其工程意义在于彻底抹除了空间中的“线程维度”。原本需要二维甚至三维坐标系来描述的寻址逻辑,在此刻坍缩为一个只与数据量大小(Size/Value)相关的极简一维函数。
4. 一维顺序执行 (1D Sequential Access)
无论最终是读取(Load)还是存储(Store),经过 partition 吐出的结果(如 Tensor Fragment),在当前线程的视角下,本质上退化成了一个“包含所有目标物理地址的 1D List”。
此时,复杂的线程并行概念已经完全消解。线程只需要按照这个“List”的 Size,通过一维索引 (i) 进行最简单的顺序迭代计算。底层编译器会利用提前算好的代数偏移量,直接生成极其高效的内存访问指令,实现榨干 Tensor Core 的极致性能。
总结:对于 partition 的理解,可以这样梳理:首先定义 TVLayout,即描述线程 T 与寄存器 V 的 ID 映射关系,通过这个 layout 可以确定当前线程需要从以 MNK 逻辑排布的内存中取哪个地址的数据;与此同时,TVCLayout 则进一步描述当前线程 ID 所计算出的结果应存放在哪个位置。值得注意的是,swizzle 等操作本身以 MNK 逻辑排布的内存作为输入,完成从逻辑地址到物理地址的映射,因此 TVLayout 可以直接叠加在其之上。partition 的本质,就是将传入的底层 layout(如经过 swizzle 变换后的物理内存布局)作为基础,在其上叠加一层 TVLayout,再根据当前线程的 ID 进行切片,最终得到该线程所需访问的全部数据。无论是读还是写,partition 后得到的结果都相当于一个地址列表——其中记录了该线程需要读取或存放的所有物理地址。通过
()运算符按序访问时,线程的概念已经完全消解,剩下的仅是按 size 顺序排列的一组物理地址,线程只需依次读写即可。
Tensor algorithms
copy
表面上,copy(src, dst) 就是把源张量拷到目标张量。
但在 CuTe 里,这件事远不只是“挨个赋值”:
src可能在 global memory,dst可能在 shared memory;- 二者逻辑 shape 相同,但物理 layout 完全不同;
- 某些架构上可以用
cp.async; - 某些情况下可以做向量化,比如 4 个 32-bit load 合成一个 128-bit load/store。
所以 copy 的真正目标不是“拷贝字节”,而是:
在逻辑上把一个 Tensor 的元素,按同一组逻辑坐标,搬到另一个 Tensor 中;至于底层怎么搬,交给 CuTe 根据类型决定。
其有两个主要重载:
copy(src, dst);
copy(copy_atom, src, dst);第一个版本让 CuTe 自己根据 src/dst 的类型选默认实现。
第二个版本允许你显式指定 Copy_Atom,也就是告诉 CuTe:这次别自己猜了,我指定你用哪种拷贝原子。
copy 不是“当前线程自己做完就结束”
copy 的并行性和同步语义,取决于参数类型。它有可能:
- 完全是每个线程自己顺序做;
- 也可能是整个 block 甚至 cluster 协同做;
- 还可能底层用了异步拷贝指令,如
cp.async或memcpy_async。
所以你绝不能想当然地认为:
“我一调用完
copy,后面立刻读dst就一定安全。”
不一定。
如果这次 copy 是多线程协作的,那你往往需要 __syncthreads();
如果这次 copy 底层走的是 cp.async,那还需要额外的 async fence / wait。
copy_if
假设你把一个 41×55 的矩阵切成 4×8 tile。 那边界 tile 一定有“残缺块”——并不是每个 tile 都满。 如果你还像整齐 tile 那样无脑去 load/store,就会越界。
CuTe 对这个问题的标准处理不是去构造“10 个满 tile + 1 个残 tile”这种复杂逻辑,而是:
仍然把它当成规则 tile 网格,只不过给每个元素附一个 predicate,越界元素不做操作。
这就是 copy_if 的意义。它和 copy 一样拿 src/dst,但会额外拿一个和它们同 shape 的 predicate Tensor。predicate 非零的位置才执行拷贝。
template <class PrdTensor, class SrcEngine, class SrcLayout, class DstEngine, class DstLayout>
CUTE_HOST_DEVICE void copy_if(PrdTensor const& pred, Tensor<SrcEngine, SrcLayout> const& src, Tensor<DstEngine, DstLayout>& dst)
{
using SrcType = typename SrcEngine::value_type;
using DstType = typename DstEngine::value_type;
CUTE_UNROLL
for (int i = 0; i < size(dst); ++i)
{
if (pred(i))
{
dst(i) = static_cast<DstType>(static_cast<SrcType>(src(i)));
}
}
}gemm
CuTe 把“乘法+归约”这件事统一成一组 按 mode 解释的张量算法。
于是 gemm 不只覆盖普通矩阵乘,还统一覆盖:
- 向量逐元素乘;
- 外积;
- 矩阵乘;
- batched 外积;
- batched 矩阵乘。
V / M / N / K
V:独立元素维度,可以理解成 batch/value 维;M、N:结果矩阵C的行和列;K:归约维,也就是求和维。
cute 规定:
- 如果有
K,它总在最右边 - 如果有
V,它总在最左边
CuTe 统一采用
A : (M,K)B : (N,K)C : (M,N)
也就是说,B 不是“按线性代数课本的二维写法”来表述,而是始终把 归约维 K 放在右边。
这样做的好处是:
- A 和 B 都把 K 放在同一个位置;
- 软件实现里“沿第二个 mode 做 reduction”会更统一;
- 不再需要脑子里不停切换“这个 B 是不是转置了”。
五种 gemm 语义
向量乘加:(V) x (V) => (V)
公式是: $$ C_v += A_v B_v $$
外积:(M) x (N) => (M,N)
$$ C_{mn} += A_m B_n $$
一个长度为 M 的向量和一个长度为 N 的向量,直接张成一个 M×N 矩阵。
矩阵乘:(M,K) x (N,K) => (M,N)
$$ C_{mn} += A_{mk} B_{nk} $$
相当于对每个 K,调用一次外积,再把结果累加。
batched 外积:(V,M) x (V,N) => (V,M,N)
每个 v 自己对应一组 A/B(向量),产生自己的一个 (M,N) 结果。
你可以把 V 想成 batch 维。
于是:
- 第 0 个 batch:做一次外积
- 第 1 个 batch:做一次外积
- …
- 每个 batch 独立
batched 矩阵乘:(V,M,K) x (V,N,K) => (V,M,N)
对每个 batch 的 (M,K) 和 (N,K) 做 GEMM。它会对每个 K 调用batched 外积操作
gemm 和 copy
gemm 和 copy 一样,会根据 Tensor 参数类型自动派发到合适实现;而且也支持额外传一个 MMA_Atom 来覆盖默认选择。
copy有Copy_Atomgemm有MMA_Atom
这背后的统一设计思想是:
高层算法接口保持不变,低层执行原子可替换。
axpby
axpby 的定义是:
$$
y = \alpha x + \beta y
$$
写成矩阵方式: $$ C = \alpha \cdot A + \beta \cdot C $$
- 可以实现:残差更新、线性组合、覆盖写回 / 累加写回 切换
fill
fill 把输出 Tensor 的每个元素都写成同一个标量值。
clear
clear 是 fill(0) 的专门版本:把输出 Tensor 全部置零。
CuTe MMA
CuTe MMA Atoms
CuTe 通过一对结构体将每条 MMA 指令暴露给通用 CUDA C++ 代码:
Operation 结构体负责描述 PTX 指令的物理接口——它定义指令所需的参数,几乎不依赖任何上层软件抽象(无 Layout、Tensor 或自定义数值类型),仅关注指令本身的输入输出。不同的 Operation 结构体以其对应 MMA 指令的功能命名。
MMA_Traits 结构体以 Operation 类型为模板参数进行特化,提供该 Operation 的元信息,包括:逻辑计算类型、操作的逻辑形状,以及操作内部线程与数据的 Layout 描述。CuTe 为每种受支持的 Operation 提供了对应的 Traits 特化实现。
两者共同构成一个 “Atom”(原子),将线程与数据布局的复杂性与 PTX 指令的调用点彻底解耦。Traits 所暴露的信息只与单次 MMA 操作的语义相关,与其实际运行的硬件粒度无关。
CuTe 目前支持以下硬件级别的 MMA 原子:
| 硬件级别 | 代表架构 |
|---|---|
| 单线程(FMA 指令) | 通用 |
| Quad-pair | Volta |
| 单 Warp | Ampere |
| Warpgroup | Hopper |
这一设计的核心价值在于语义与实现的分离:上层代码只需面向统一的 Atom 接口编程,无需关心底层指令在不同架构上的调度差异。
Operation结构体
Operation结构体的命名
例如,下面Volta部分会引用include/cute/arch/mma_sm70.hpp中定义的SM70_8x8x4_F32F16F16F32_NT Operation结构体。
• “SM70”指Volta。
• “8x8x4”指M=8、N=8、K=4,即quadpair执行的MMA操作维度(见下文)。这反映在PTX中为.m8n8k4.。
• “F32F16F16F32”指四个矩阵操作数A、B、C、D的元素类型。MMA计算D = C + A * B,所以从左到右读取类型:D是F32(float),A是F16(half),B是F16(half),C是F32(float)。这反映在PTX指令名中为.f32.f16.f16.f32。
• “NT”表示PTX指令为A输入M-major(不转置,列主序)和B输入N-major(转置,行主序)。这反映在PTX指令名中为.col.row.。
内容
Operation结构体有四个公开类型别名:DRegisters、ARegisters、BRegisters、CRegisters。
例如,SM70_8x8x4_F32F16F16F32_NT结构体定义如下:
using DRegisters = float[8];
using ARegisters = uint32_t[2];
using BRegisters = uint32_t[2];
using CRegisters = float[8];这显示了每个线程将向PTX指令传递的每个矩阵A、B、C、D的值的数量。对于这个Operation,每个线程为C和D各传递8个F32值(因此float[8]),为A和B各传递4个F16值(因此uint32_t[2];指令把两个16位F16值打包进每个32位uint32_t)。
fma静态成员设备函数
Operation结构体定义一个公开的static void fma函数。它用CUTE_HOST_DEVICE宏标记,添加__host__ __device__注解。不同的Operation根据PTX MMA指令定义不同参数数量的fma。实现用宏保护PTX指令的使用,如果宏未定义则引发assert。这保证即使PTX指令不可用,使用该Operation的Atom的测试和示例仍能编译。
Traits
内容
MMA_Traits特化定义以下公开类型别名。
• ValTypeD:D矩阵的逻辑计算类型
• ValTypeA:A矩阵的逻辑计算类型
• ValTypeB:B矩阵的逻辑计算类型
• ValTypeC:C矩阵的逻辑计算类型
• Shape_MNK:MMA操作的逻辑MxNxK形状
• ThrID:单个MMA操作内的逻辑线程映射(指定线程、quadpair、warp或warpgroup视图)
• ALayout:(thread,value)对到MxK A矩阵坐标的映射
• BLayout:(thread,value)对到NxK B矩阵坐标的映射
• CLayout:(thread,value)对到MxN C矩阵坐标的映射
例子
SM70_8x8x4_F32F16F16F32_NT Operation的MMA_Traits特化位于头文件include/cute/atom/mma_traits_sm70.hpp。它看起来像这样:
template <>
struct MMA_Traits<SM70_8x8x4_F32F16F16F32_NT>
{
using ValTypeD = float;
using ValTypeA = half_t;
using ValTypeB = half_t;
using ValTypeC = float;
using Shape_MNK = Shape<_8,_8,_4>;
using ThrID = SM70_QuadPair;
using ALayout = SM70_8x4_Col;
using BLayout = SM70_8x4_Col;
using CLayout = SM70_8x8_32b;
};Volta
本节以及后续章节展示如何构造MMA原子。
Volta架构实现了一个HMMA指令,由8个线程组成的一个quadpair(QP)协作共享数据并执行8x8x4(fp32或fp16)的矩阵乘累加。(由于一个warp有32个线程,它会跨4个QP执行一个16x16x4的MMA。)
我们首先看看如何把HMMA指令的ISA线程和数据分区语义编码到Traits结构体中。HMMA NT指令的线程-数据布局如下:
类型
HMMA NT使用的类型为:
using ValTypeD = float;
using ValTypeA = half_t;
using ValTypeB = half_t;
using ValTypeC = float;MMA_Traits的其余部分都以这些类型为单位描述。
形状
HMMA NT的形状为8x8x4:
// MMA的逻辑形状
using Shape_MNK = Shape <_8,_8,_4>;线程ID
如果warp的32个线程逻辑索引为[0 … 31],则上图包含线程[0,1,2,3]U[16,17,18,19]。这些线程构成第0个quadpair。我们可以写一个线程映射,把MMA的8个逻辑线程id [0,1,2,3,4,5,6,7]映射到warp中quadpair的线程索引[0,1,2,3]U[16,17,18,19]。布局函数有4个元素步长为1,另外2个步长为16。于是我们写出表示quadpair的布局:
// (逻辑线程id) -> (线程索引)
using ThrID = Layout<Shape <_4, _2>,
Stride<_1,_16>>;这个布局函数将MMA操作的逻辑线程id [0,8) 映射到warp中quadpair的线程索引 [0,4)U[16,20)。
累加器映射
让我们精确看看QP内8个线程如何映射到A、B和C矩阵。对于C和D矩阵,上图进一步拆解如下。左边是整个QP视图,右边是仅线程0拥有的值。
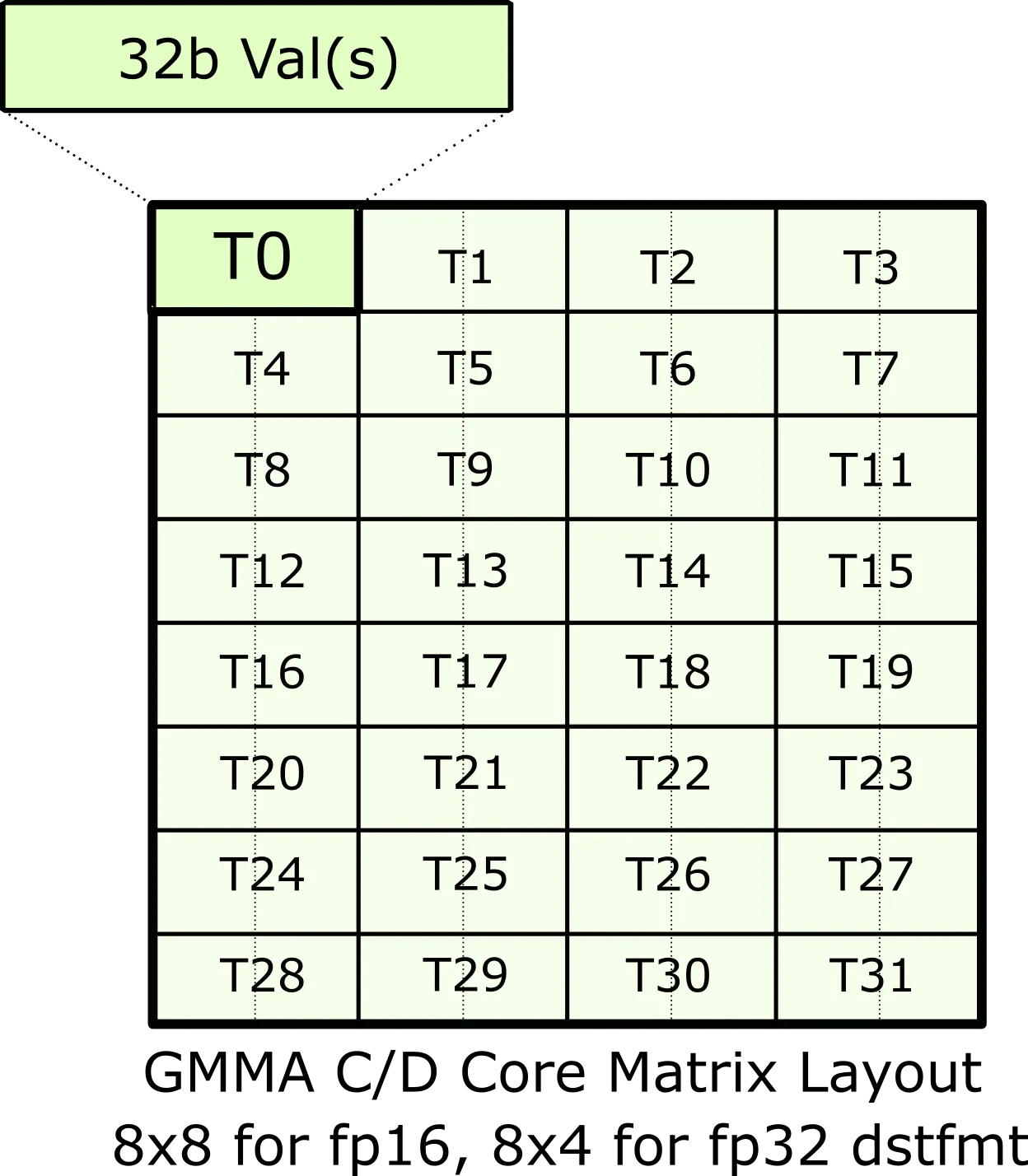
这个单指令级别视图的元信息正是我们想在CuTe中编码的内容。具体来说,上图中的QP级别视图对应SM70_F32F16F16F32的四个MMA traits。这些结构体包含元素类型、Shape_MNK以及我们上面构造的ThrID映射。现在来看CLayout——累加器的线程-数据布局。CLayout的任务是在(logical_thr_id, logical_val_id)与C矩阵的(m, n)坐标之间建立映射,以便后续构建更复杂的布局和操作(如16x16x4 WMMA)。
我们从上图开始构造CLayout。和任何CuTe布局一样,它是Shape与对应Stride的组合。先看形状。我们知道HMMA使用8个线程,每个线程拥有8个值。因此映射的形状在两个模式上大小必须为8:
// (T8,V8) -> (m,n)
using CLayout = Layout<Shape <_8, _8>,
Stride<_?, _?>; // Stride待填充这不是C矩阵的逻辑8x8形状,而是8线程×8值的形状。现在我们要把它映射到(m,n)坐标。因为CuTe布局返回索引而非坐标,我们选择列主序编码(m,n)坐标:
(logical_thr_id, logical_val_id) -> (m, n) == m + n * M现在开始构造CLayout的stride。先看线程间的stride。注意:
(T0,V0)位于(m,n)=(0,0)=0(T1,V0)位于(m,n)=(1,0)=1(T2,V0)位于(m,n)=(0,2)=16(T3,V0)位于(m,n)=(1,2)=17(T4,V0)位于(m,n)=(4,0)=4- ……(以此类推)
我们发现模式可以转录为布局。8个线程的位置为:
using CLayout = Layout<Shape <Shape <_2, _2, _2>, _8>,
Stride<Stride<_1, _16, _4>, _?>;用完全相同的方法构造logical value id模式的stride:
// (T8,V8) -> (m,n)
using CLayout = Layout<Shape <Shape <_2, _2,_2>, Shape <_2,_2, _2>>,
Stride<Stride<_1,_16,_4>, Stride<_8,_2,_32>>>;这样就完成了!我们可以验证每个(tid,vid)坐标都能可靠映射到正确的编码(m,n)坐标。
对于该CLayout
输入 (Input)
它的输入是一个二元组:
(Logical Thread ID, Logical Value ID)。
- Logical Thread ID (tid):逻辑线程编号(在这个例子中是0到7)。
- Logical Value ID (vid):该线程持有的寄存器(数据)编号(在这个例子中是0到7)。
输出 (Output)
它的输出是一个线性索引 (Linear Index)。
这个索引代表了该数据在 8x8 矩阵中的一维偏移量,通常映射到二维坐标 (m, n):
$$ Index = m + n \times 8 $$ 通过这个输出,程序就能知道:“第 i 个线程的第 j 个寄存器值,对应矩阵里第 m 行、第 n 列的元素。”
如果是F16累加器,布局要简单得多。每行累加器(m, :)由单个线程持有,布局为:
using CLayout = Layout<Shape <_8,_8>,
Stride<_1,_8>>;A和B布局映射
A和B矩阵布局取决于源是否转置。下图显示NT和TN转置情况下A和B矩阵的线程ID到数据所有权映射。
先看TN布局的A矩阵(图右侧)。同样是8个逻辑线程,但每个线程只拥有4个元素。ALayout的形状为Shape<_8, _4>。stride方面,我们需要(m, k) == m + k * M的映射。沿M模式看,从(T0, V0)到(T1, V0)步长为1(对所有8线程)。沿K模式,从(T0, V0)到(T0, V1)步长为8(对4个值)。因此A布局为:
// (T8,V4) -> (m,k)
using ALayout = Layout<Shape <_8,_4>,
Stride<_1,_8>>;B布局类似,只是我们为了方便写成(N,K)而非(K,N)。最终B布局与A相同:
// (T8,V4) -> (n,k)
using BLayout = Layout<Shape <_8,_4>,
Stride<_1,_8>>;NT情况的布局更复杂(图左侧)。沿A的M模式,先看到T0的4个值,再看到T4的4个值。因此M模式有两段子stride。对于K模式,简单递增thr_id,val_id不变,步长为8(对4线程)。于是A布局为:
// (T8,V4) -> (m,k)
using ALayout = Layout<Shape <Shape <_4,_2>,_4>,
Stride<Stride<_8,_4>,_1>>;B布局相同。NN和TT转置则是我们已见两种布局的简单组合。
Hopper
现在我们可以来看Hopper架构首次引入的更大GMMA操作(Group MMA)。这些MMA指令以128线程(4个warp)为粒度运行,统称为warpgroup。
线程ID
Hopper GMMA中线程ID基于简单1D连续布局,因此ThrID非常简单:
using ThrID = Layout<_128, _1>;累加器映射
GMMA中累加器分层映射,从核心矩阵开始逐步构建整个C矩阵tile。我们先看核心矩阵(这里只考虑fp16累加器,fp32扩展后面会看到,非常简单)。
每个核心矩阵布局如下图所示:
和Volta例子一样,线程ID只是逻辑的,四个warp的归属不重要。
然后GMMA先沿M模式垂直平铺核心矩阵,再沿N模式重复该列核心矩阵,构成完整的MxN tile。平铺如下图:
有了这张图,我们就可以开始为SM90_64x128x16_F16F16F16F16_TN原子构建CLayout。同样,我们在(logical_thr_id, logical_val_id) -> (m, n)坐标空间建立映射。
先跟随前几个线程和值。我们立刻看到它们沿N模式以值对和4线程排列,于是:
// (T128,V4) -> (M64,N8)
using CLayout = Layout<Shape <Shape < _4, ...>, Shape < _2, ...>>,
Stride<Stride<_128, ...>, Stride<_64, ...>>>;完成第一个8x8核心矩阵:4个线程沿M模式重复8次:
// (T128,V4) -> (M64,N8)
using CLayout = Layout<Shape <Shape < _4, _8, ...>, Shape < _2, ...>>,
Stride<Stride<_128, _1, ...>, Stride<_64, ...>>>;下一个核心矩阵时回到T0,但这次是(T0, V2):
// (T128,V4) -> (M64,N8)
using CLayout = Layout<Shape <Shape < _4, _8, ...>, Shape < _2, _2>>,
Stride<Stride<_128, _1, ...>, Stride<_64, _8>>>;最后,整个模式在M模式重复4次(每个warp一次),从(m,n)=(16,0)=16开始。这使得thrID最后子模式的尺寸为4(4个warp),步长为16。于是最终64x8累加器的CLayout为:
// (T128,V4) -> (M64,N8)
using CLayout = Layout<Shape <Shape < _4, _8, _4>, Shape < _2, _2>>,
Stride<Stride<_128, _1, _16>, Stride<_64, _8>>>;//相当于1个图中那样的 8 列宽的块GMMA指令包含64xN变体(N=[16,32,64,128,256]),该64x8模式重复,给每个线程更多值。从(m,n)=(0,8)=512开始,非常容易在CLayout中处理。例如64x128的CLayout为:
// (T128,V64) -> (M64,N128)
using CLayout = Layout<Shape <Shape < _4, _8, _4>, Shape < _2, _2, _16>>,
Stride<Stride<_128, _1, _16>, Stride<_64, _8, _512>>>;//相当于16个图中那样的 8 列宽的块A和B布局映射
直接从共享内存消费A和B的GMMA原子比较特别。GMMA Descriptor是在整个共享内存tile上构造的,而不是按线程分区。也就是说每个线程都能看到整个tile,tile不会被重排序以便构造Descriptor。在ALayout形式中可以表示为:
// (T128,V64x16) -> (M64,K16)
using ALayout = Layout<Shape <_128, Shape <_64,_16>>,
Stride< _0, Stride< _1,_64>>>;//输入为(m, k),因此第二个shape需要二维即所有线程都映射到(m,k)=(0,0)=0元素,值(和值的形状)保持不变。GMMA Descriptor构造器随后可以检查该数据的(M,K)布局,创建合适的Descriptor或报错。
TiledMMAs
TiledMMA 的出发点
在 CuTe 中,单个 MMA_Atom(比如 Volta 的 SM70_8x8x4_F32F16F16F32_NT)只能处理非常小的矩阵块(8×8×4)。但实际 GEMM 需要更大的 tile(比如 16×16×4、32×32×4),而且希望线程对数据的访问更“连续”(比如共享内存或寄存器中连续存放),这样才能获得更好的加载性能和更少的 bank conflict。
TiledMMA 的核心目的就是:
- 把多个
MMA_Atom组合(replicate)成更大的计算单元; - 通过 Layout of Atoms 决定这些原子在线程间的排列方式;
- 通过 Tile 参数 对 M/N/K 三个模式分别进行复制或置换(permutation),让线程看到的数据布局更友好。
这就是 make_tiled_mma 函数的全部意义:把小原子“拼”成大图案,同时还能“重排”坐标。
原理讲解
TiledMMA mma = make_tiled_mma(
BaseAtom{}, // 1. 基础原子(Operation + Traits)
Layout_of_Atoms{}, // 2. 原子在线程间的排列(决定线程复制)
Tile_MNK{} // 3. 对 M/N/K 模式分别做“复制或置换”
);-
第 2 个参数(Layout of Atoms):告诉 CuTe “把这个原子复制成几行几列”。
比如Layout<Shape<_2,_2>, Stride<_2,_1>>{}表示:- 2×2 共 4 个原子;
- 排列方式是 n-major(列优先):先填完一列,再填下一列。
- 结果:原来 8 个线程的原子,现在变成 32 个线程(4 个 quadpair)。
-
第 3 个参数(Tile):对 M、N、K 三个模式分别处理。
- 可以是
Shape<...>(简单复制); - 也可以是
Layout<Shape<...>, Stride<...>>(置换,把旧坐标映射到新坐标)。 - 置换的本质是“散射”(scatter):告诉 CuTe “原来的第 i 个 m 坐标,现在应该放在第 j 个位置”。
先看看下面这个例子:
- 可以是
TiledMMA mma = make_tiled_mma(
SM70_8x8x4_F32F16F16F32_NT{},
Layout<Shape<_2,_2>, Stride<_2,_1>>{}, // 2×2 n-major 原子排列
Tile<Layout<Shape<_4,_4,_2>, Stride<_1,_8,_4>>, // ← 对 M 模式的置换
_32, // 对 N 模式的身份(不改变)
_4>{} // 对 K 模式的身份
);这个 Layout<Shape<_4,_4,_2>, Stride<_1,_8,_4>> 到底在做什么?
-
先看形状:
Shape<_4,_4,_2>说明最终 M 模式的大小是4×4×2 = 32(和我们想要的 32×32×4 tile 匹配)。 -
再看步长(Stride):
Stride<_1,_8,_4>是置换规则:- 第一个
_4用 stride 1; - 第二个
_4用 stride 8; - 第三个
_2用 stride 4。
- 第一个
-
实际映射表(文档原表):
旧 m 坐标(0~31): 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
新 m 坐标(重排后): 0 1 2 3 8 9 10 11 16 17 18 19 24 25 26 27 4 5 6 7 12 13 14 15 20 21 22 23 28 29 30 31直观效果:
- 原来线程 T0 的 8 个 A-matrix 值分散在 (0,0)~(19,0);
- 重排后,这 8 个值全部连续(m=0~7)。
这就是置换的威力!它让后续共享内存布局或寄存器加载变得连续,极大提升性能。
举几个例子:
以SM70_8x8x4_F32F16F16F32_NT为例:
MMA_Atom mma = MMA_Atom<SM70_8x8x4_F32F16F16F32_NT>{};
print_latex(mma);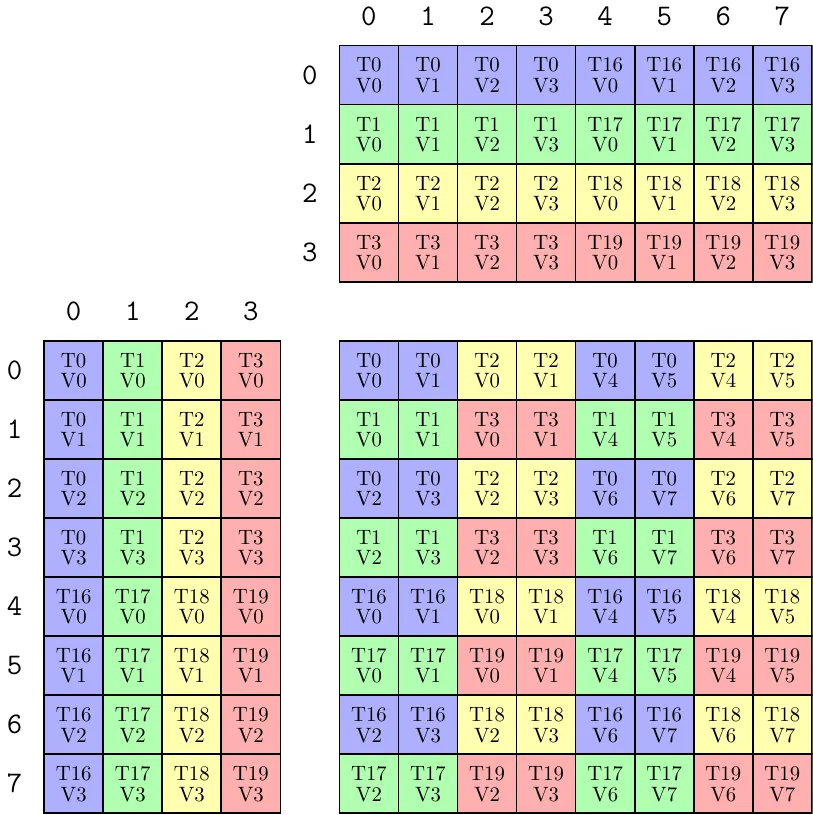
上面等价于:
TiledMMA mma = make_tiled_mma(SM70_8x8x4_F32F16F16F32_NT{},
Layout<Shape<_1,_1,_1>>{}, // Atom布局
Tile<_8,_8,_4>{}); // Tiler我们可以用4个这样的quadpair MMA创建一个类似WMMA的对象:
TiledMMA mma = make_tiled_mma(SM70_8x8x4_F32F16F16F32_NT{},
Layout<Shape <_2,_2>, Stride<_2,_1>>{}); // 2x2 n-major Atom布局
这个TiledMMA把MMA_Atom跨线程复制(可以看到之前没用到的T4、T8、T12线程)。每个C矩阵象限都是新quadpair的原子分区模式的副本,复制遵循(2,2):(2,1)布局。
上面现在表示16x16x4 MMA,我们可以立即把“tile size”扩展到32x32x4:
TiledMMA mma = make_tiled_mma(SM70_8x8x4_F32F16F16F32_NT{},
Layout<Shape <_2,_2>, Stride<_2,_1>>{},
Tile<_32,_32,_4>{});
这个TiledMMA把前一个TiledMMA跨值(而非线程)复制。
继续,我们看到T0从A矩阵收到8个值,坐标分散。我们希望把它们排在一起,于是对M模式做置换:
TiledMMA mma = make_tiled_mma(SM70_8x8x4_F32F16F16F32_NT{},
Layout<Shape <_2,_2>, Stride<_2,_1>>{},
Tile<Layout<Shape <_4,_4,_2>, Stride<_1,_8,_4>>, _32, _4>{});
这个置换只影响M模式(A和C相应变化),让所有线程在A矩阵的m坐标上连续访问,非常适合共享内存或寄存器布局设计。
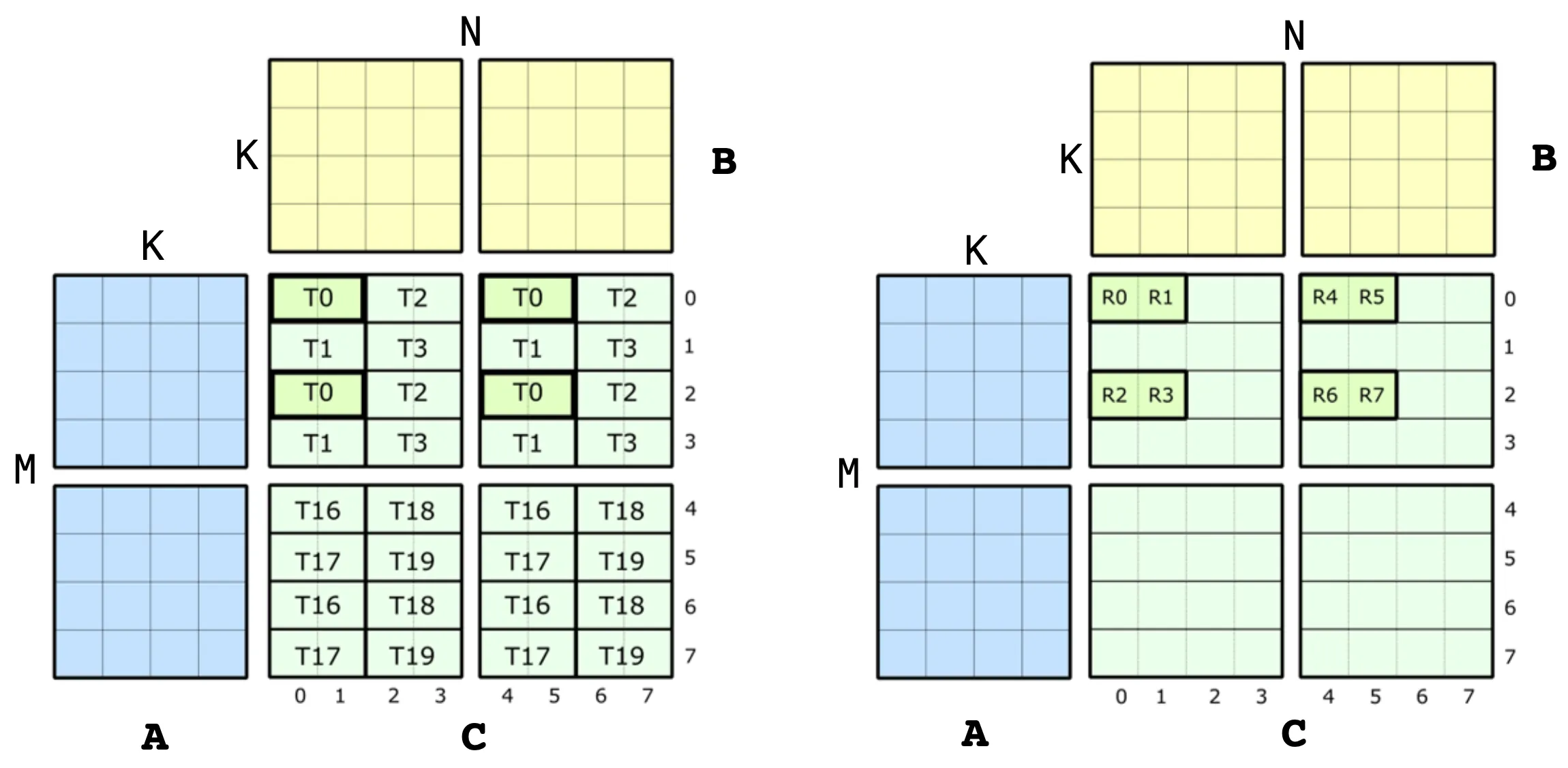
sgemm
矩阵乘法的两阶段执行:数据搬运与计算
矩阵乘法的执行分为**数据搬运(Load)和矩阵计算(Compute)**两个阶段。值得注意的是,这两个阶段对线程的组织方式完全不同——同一批线程在不同阶段会以不同的布局方式参与工作。
问题规模与 CTA 划分
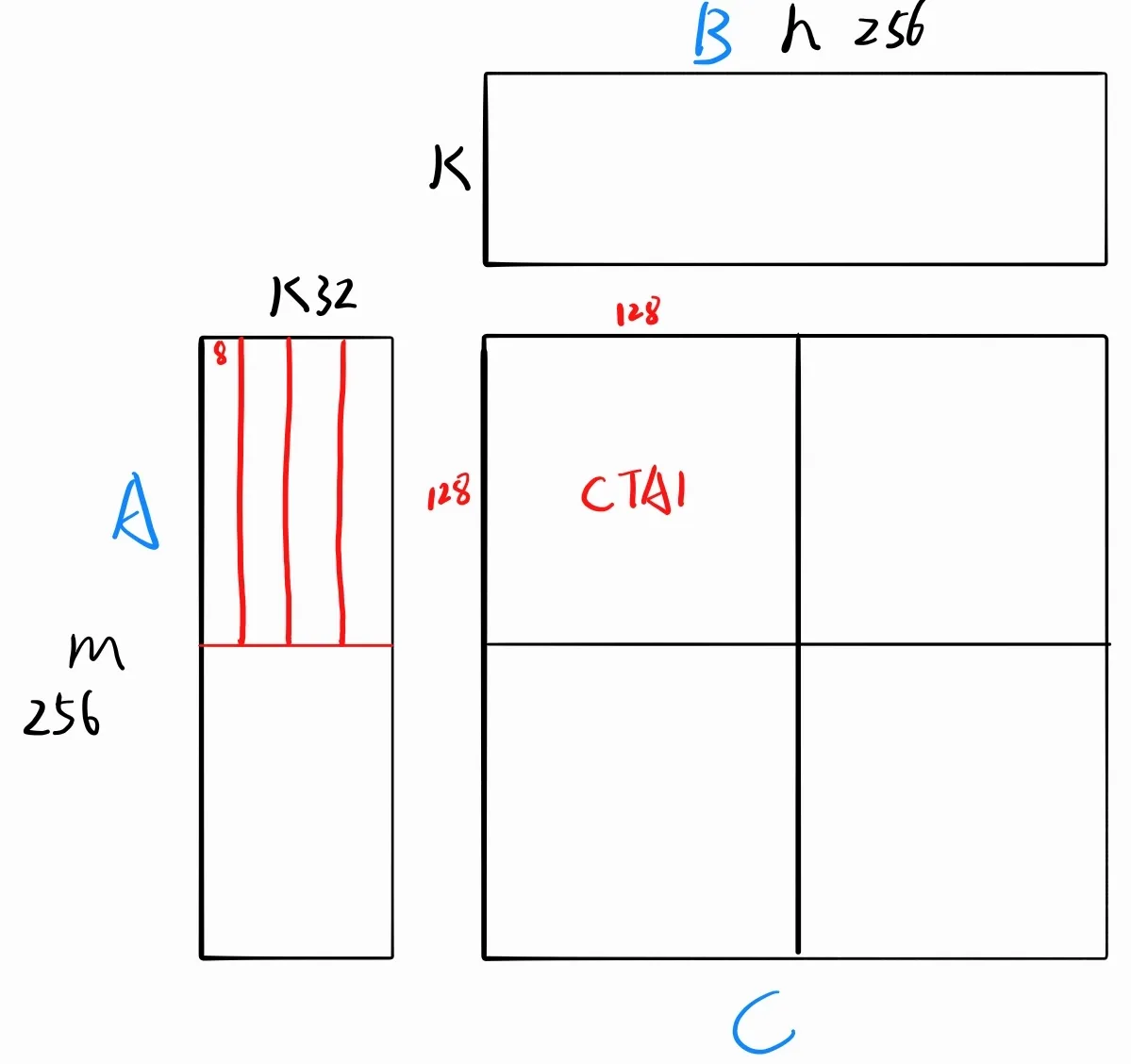
以一个 256×256 的输出矩阵 C 为例。我们规定每个 CTA(Block)负责 C 的 128×128 输出块的计算与写回,同时负责把对应的 A 128×32 和 B **128×32 **搬运到共享内存。因此,整个矩阵需要 (2, 2) = 4 个 CTA 协同完成全部计算。
对于每个 CTA,其所负责的 128×128 输出块决定了它需要从全局内存中读取的数据范围:
- A 矩阵:对应 128×32 的子块(其中 32 为规约维度 K)
- B 矩阵:对应 32×128 的子块(同理)
第一阶段:数据搬运(Load)
由于共享内存(Shared Memory)空间有限,无法一次性容纳完整的 128×32 数据块,因此将其沿 K 维度拆分为 4 个 128×8 的小块,每个小块称为一个 Tile。CTA 循环搬运 4 次,每次处理一个 Tile,共完成整段数据的搬运。
在此阶段,每个 Block 内开启 256 个线程,采用 32×8 的线程布局。对于每次单个 Tile(128×8)的搬运任务,线程与数据的对应关系为:每个线程负责搬运 (4, 1) 大小的数据片段。32×8 的线程网格覆盖整个 128×8 的 Tile,从而实现并行搬运。B 矩阵的搬运方式与此完全对称。
第二阶段:矩阵计算(Compute)
数据搬运完成后,进入计算阶段。此时线程布局切换为 16×16,与搬运阶段的布局完全不同。
在此布局下,CTA 负责的 128×128 输出块被均匀分配给 256 个线程,每个线程负责计算 8×8 大小的输出子块。
由于共享内存每次只能容纳一个 Tile 的数据,计算同样需要循环 4 次,与 Load 阶段的循环一一对应:
每次迭代 = Load 一个 Tile → 基于当前 Tile 计算 8×8 的部分结果 → 累加到线程私有的寄存器变量中
后续每次 Load 都会用新数据覆盖共享内存中上一轮的内容,但累加器中的中间结果已被安全保存在寄存器里。4 次循环结束后,每个线程的累加器中存储的便是其所负责的 8×8 输出块的最终结果(共 64 个值)。
最终,每个线程将自己独立计算得到的 8×8 结果写回全局内存,完成整个计算流程。
local_tile
// Represent the full tensors
Tensor mA = make_tensor(make_gmem_ptr(A), select<0, 2>(shape_MNK), dA); // (M,K)
Tensor mB = make_tensor(make_gmem_ptr(B), select<1, 2>(shape_MNK), dB); // (N,K)
Tensor mC = make_tensor(make_gmem_ptr(C), select<0, 1>(shape_MNK), dC); // (M,N)
// Get the appropriate blocks for this thread block
auto cta_coord = make_coord(blockIdx.x, blockIdx.y, _); // (m,n,k)
Tensor gA = local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{}); // (BLK_M,BLK_K,k)
Tensor gB = local_tile(mB, cta_tiler, cta_coord, Step<X, _1, _1>{}); // (BLK_N,BLK_K,k)
Tensor gC = local_tile(mC, cta_tiler, cta_coord, Step<_1, _1, X>{}); // (BLK_M,BLK_N)其中local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{});等价于:
Tensor gA = local_tile(mA, select<0,2>(cta_tiler), select<0,2>(cta_coord));//gA(128,8,512)
// (M,K) (BLK_M, BLK_K) (m, k)
// 含义:将 mA 按照 (BLK_M, BLK_K) 进行 zipped_divide,
// 再用 select<0,2>(cta_coord) = (m, _) 在rest-mode选取指定tile:
// 其中 m 指定当前 CTA 在 M 维度上的分块索引(固定),
// _ 表示 K 维度全选(保留所有分块),
// 最终结果的 shape 为 (BLK_M, BLK_K, k),
// 即当前 CTA 负责的 A 子块在 M 方向已定位,K 方向保留完整分块序列。再具体点就是:
Tensor gA_mk = zipped_divide(mA, select<0,2>(cta_tiler));//((BLK_M, BLK_K), (m, k))
Tensor gA = gA_mk(make_coord(_,_), select<0,2>(cta_coord));local_partition
auto tA = make_layout(make_shape(Int<32>{}, Int<8>{})); // (m,k) -> thr_idx
Tensor tAgA = local_partition(gA, tA, threadIdx.x);//gA(BLK_M, BLK_K, k) tAgA(THR_M,THR_K,k)
// Partition sA (BLK_M, BLK_K) by the rows of tC
Tensor sA = make_tensor(make_smem_ptr(smemA), sA_layout); // (BLK_M,BLK_K)
Tensor tCsA = local_partition(sA, tC, threadIdx.x, Step<_1, X>{}); // (THR_M,BLK_K)其与local_tile的区别是:
local_tile是在 2-mode 上切片local_partition是在 1-mode 上切片
具体过程
local_tile 解释
local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{}) 的语义是:
对张量 mA(整个 A 矩阵)按照 select<0,2>(cta_tiler) 所指定的 tile 尺寸进行 zipped_divide,将矩阵在对应维度上切分为若干 tile 块;随后在2-mode索引维度上,根据 select<0,2>(cta_coord) 取出对应位置的子张量,从而返回当前 CTA 所负责的所有 tile。
以具体形状为例:zipped_divide 后张量变为 ((BLK_M, BLK_K), (m, k)),其中:
- 内层
(BLK_M, BLK_K)是单个 tile 的形状,与select<0,2>(cta_tiler)一致; - 外层
(m, k)是 tile 的网格索引,如m=2(A 沿 M 方向被切成 2 块)、k=4(沿 K 方向被切成 4 块)。
Step<_1, X, _1> 控制哪些维度参与切分(X 表示该维度不参与),最终通过 cta_coord 索引选出当前 CTA 对应的所有 tile。本质上,local_tile 是全局矩阵到 tile 粒度的划分,输入是整张矩阵。
local_partition 解释
local_partition(sA, tC, threadIdx.x, Step<_1, X>{}) 的语义是:
对张量 sA(一个 tile 大小的 shared memory 片段)按照 select<0>(tC) 所指定的线程布局尺寸进行 zipped_divide,将 tile 在对应维度上切分为若干线程负责的小块;随后将 threadIdx.x 映射到 tC 的多维线程坐标,并取其第 0 维的索引,从1-mode索引维度中选出当前线程负责的那部分数据。
以具体形状为例:zipped_divide 后张量变为 ((16), (THR_M, BLK_K)),其中:
- 内层
(16)是线程在16x16布局(计算布局)下的二维坐标中的一个维度的坐标,与select<0>(tC)的 shape 一致,用于选取线程; - 外层
(THR_M, BLK_K)是一个线程负责的子张量,如THR_M = BLK_M / 16 = 8(M 方向由 8 个线程瓜分)、BLK_K = 8(K 方向不切分,保留 tile 的完整 K 长度)。
Step<_1, X> 同样控制参与切分的维度,最终通过线程坐标索引取出当前线程在 tile 内应读取的数据。
local_partition(gA, tA, threadIdx.x) 的语义是:
对张量 gA(全局内存中当前 CTA 负责的所有 tile 窗口)按照 tA 所指定的线程布局尺寸进行 zipped_divide,将 tile 在对应维度上切分为若干线程负责的小块;随后将 threadIdx.x 映射到 tA 的多维线程坐标,从1-mode索引维度中选出当前线程负责的那部分数据。
以具体形状为例:zipped_divide 后张量变为 ((32, 8), (THR_M,THR_K,k)),其中:
(32, 8)是线程在32x8布局(数据搬运布局)下的二维坐标,与tA的 shape 一致;(THR_M,THR_K,k)是一个线程负责的所有子张量,如THR_M = BLK_M / 32= 4(M 方向由 32 个线程瓜分)、BLK_K/8 = 1(K 方向由 8 个线程瓜分),由于tA是二维,因此divide只对BLK_M,BLK_K操作,所以k不受影响,具体可见divide章。
本质上,local_partition 是 tile 内部到线程粒度的划分,输入是单个 tile,输出是每个线程独占的数据视图。
两者对比
local_tile | local_partition | |
|---|---|---|
| 输入 | 整张矩阵 | 单个 tile(shared memory) |
| 划分粒度 | Tile 级别(CTA 粒度) | 线程级别(Thread 粒度) |
| 索引依据 | cta_coord(CTA 坐标) | threadIdx.x(线程 ID) |
| 输出 | 当前 CTA 负责的 tile | 当前线程负责的数据片段 |
Cute支持将一个线程以多种布局方式来看待,从而能实现搬运和计算两种布局,来更方便的使用分配线程,其中由于线程是单维度定义,所以threadIdx.x就可以索引到所有线程
sgemm_1.cu最简实现
#include <cute/tensor.hpp>
using namespace cute;
__global__ void gemm_kernel(
int M, int N, int K, float const* A, int ldA, float const* B, int ldB, float* C, int ldC, float alpha, float beta)
{
// 1. 全尺寸 Tensor
Tensor mA = make_tensor(make_gmem_ptr(A), make_shape(M, K), make_stride(1, ldA)); // (M,K) m-major
Tensor mB = make_tensor(make_gmem_ptr(B), make_shape(N, K), make_stride(1, ldB)); // (N,K) n-major
Tensor mC = make_tensor(make_gmem_ptr(C), make_shape(M, N), make_stride(1, ldC)); // (M,N)
// 2. CTA 分块
auto cta_tiler = make_shape(Int<128>{}, Int<128>{}, Int<8>{}); // (BLK_M, BLK_N, BLK_K)
auto cta_coord = make_coord(blockIdx.x, blockIdx.y, _); // (m,n,k) 只取当前 CTA 的块
Tensor gA = local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{}); // (128,8,k)
Tensor gB = local_tile(mB, cta_tiler, cta_coord, Step<X, _1, _1>{}); // (128,8,k)
Tensor gC = local_tile(mC, cta_tiler, cta_coord, Step<_1, _1, X>{}); // (128,128)
// 3. SMEM 分配 + Tensor
__shared__ float smemA[128 * 8];
__shared__ float smemB[128 * 8];
Tensor sA = make_tensor(make_smem_ptr(smemA), make_layout(make_shape(128, 8))); // m-major
Tensor sB = make_tensor(make_smem_ptr(smemB), make_layout(make_shape(128, 8))); // n-major
// 4. 线程分区
auto tA = make_layout(make_shape(Int<32>{}, Int<8>{})); // 32×8 线程
auto tB = make_layout(make_shape(Int<32>{}, Int<8>{}));
auto tC = make_layout(make_shape(Int<16>{}, Int<16>{})); // 16×16 线程
Tensor tAgA = local_partition(gA, tA, threadIdx.x); // 每个线程拿 (4,1,k),只有带g的有整体tile"视角",即能取到所有批次的tile
Tensor tAsA = local_partition(sA, tA, threadIdx.x);
Tensor tBgB = local_partition(gB, tB, threadIdx.x);
Tensor tBsB = local_partition(sB, tB, threadIdx.x);
// 5. 计算分区
Tensor tCsA = local_partition(sA, tC, threadIdx.x, Step<_1, X>{}); // (16,8)
Tensor tCsB = local_partition(sB, tC, threadIdx.x, Step<X, _1>{}); // (16,8)
Tensor tCgC = local_partition(gC, tC, threadIdx.x, Step<_1, _1>{}); // (16,16)
Tensor tCrC = make_tensor_like(tCgC); // 寄存器累加器
clear(tCrC); // 清零
// 6. Mainloop
for (int k_tile = 0; k_tile < size<2>(tAgA); ++k_tile)
{
//相同布局视角才能互相copy,如tA才能相互copy,而不同的内存位置可以相互copy,只要布局视角相同就行,如gA和sA
copy(tAgA(_, _, k_tile), tAsA); // gmem → smem
copy(tBgB(_, _, k_tile), tBsB);
cp_async_fence();
cp_async_wait<0>();
__syncthreads();
//同时计算时也一定是同样布局视角tC
gemm(tCsA, tCsB, tCrC); // SMEM GEMM
__syncthreads();
}
// 7. Epilogue(axpby)
axpby(alpha, tCrC, beta, tCgC);
}
// 主机端启动
void gemm_nt(
int m, int n, int k, float alpha, float const* A, int ldA, float const* B, int ldB, float beta, float* C, int ldC)
{
auto cta_tiler = make_shape(Int<128>{}, Int<128>{}, Int<8>{});
dim3 grid(ceil_div(m, 128), ceil_div(n, 128));
dim3 block(256); // 16×16=256 线程
gemm_kernel<<<grid, block>>>(m, n, k, A, ldA, B, ldB, C, ldC, alpha, beta);
}
make_tiled_copy 和make_tiled_mma
在 sgemm_1 里,local_partition 已经能做两件事:
- 把 tile 按线程划分,用于搬运
- 把 tile 按线程划分,用于计算
也就是说,sgemm_1 的思路是:
先给一个线程布局
tA / tB / tC,再用local_partition把 tensor 切给线程。
这个方法足够简单,但是它有两个问题:
第一个问题:它只表达“线程怎么分”,不表达“指令怎么吃”
例如:
- 搬运时,我可能希望一条指令一次搬
128 bit - 计算时,我可能希望一条指令一次做一个
mma/fma atom
而 local_partition 本身并不关心这个,它只负责:
“把数据按线程布局切开”
它不负责:
“这个切法是否正好适配某条 copy 指令 / mma 指令”
第二个问题:搬运布局和计算布局,本来就不是一回事
例如同一个 CTA:
- 搬运 A/B 时,可能希望线程按
32x8来排 - 计算 C 时,可能希望线程按
16x16来排 - shared memory 的排布,可能又希望为了避免 bank conflict 而单独修改
所以 sgemm_2 引入了两个新东西:
make_tiled_copy:专门描述 搬运阶段make_tiled_mma:专门描述 计算阶段
它们的本质都是:
不再只是“按线程切 tensor”,而是“按指令的吃法 + 线程布局”一起切 tensor。
make_tiled_copy 解释
先看这句:
TiledCopy copyA = make_tiled_copy(
Copy_Atom<UniversalCopy<uint128_t>, TA>{},
Layout<Shape<_32,_8>>{},
Layout<Shape<_4,_1>>{}
);这句不是在切 tensor。
它只是先构造出一个“搬运规则对象” copyA。
所以你要先记住:
make_tiled_copy(...)的输出不是某个子张量,而是一个“如何按 copy 指令去分块”的规则。
语义
make_tiled_copy(copy_atom, thr_layout, val_layout) 的语义是:
先定义一个最小搬运原子 copy_atom,再定义这个原子如何在线程维度和值维度上重复铺开,从而形成一个 TiledCopy 分区器。这个分区器之后可以作用在 source tensor 和 destination tensor 上,分别得到当前线程该读什么、该写什么。
第一步:定义 copy atom
Copy_Atom<UniversalCopy<uint128_t>, TA>{}它表示:
一条底层 copy 指令,按
uint128_t这个粒度去搬数据。
如果 TA=float,那:
- 一个
float= 32 bit - 一个
uint128_t= 128 bit - 所以一条 copy atom 一次搬 4 个 float
这一步的目的,是先规定:
单条搬运指令一次吃几个元素
这是 sgemm_1 里 tA/tB 完全没有表达的东西。
第二步:定义线程布局
Layout<Shape<_32,_8>>{}它表示:
在这套 copy 规则里,线程被看成一个
32 x 8的二维布局。
也就是 256 个线程。
这一步的目的,是规定:
这些 copy atom 由哪些线程来执行,以及线程在 tile 中怎么排
它对应的,其实就是 sgemm_1 里的 tA 或 tB,但这里只是“线程排布”这一层。
第三步:定义每个线程携带的值布局
Layout<Shape<_4,_1>>{}它表示:
每个线程,不是只搬 1 个值,而是搬一个
4x1的小块。
因为前面 copy atom 已经规定了一条指令一次搬 4 个 float,所以这里的 4x1 正好和它对上。
这一步的目的,是规定:
每个线程在一次 copy 里,拿哪几个逻辑元素
于是前两步合起来,就从“线程怎么排”上升成了:
线程怎么排,并且每个线程一次按什么打包方式搬数据
第四步:给当前线程取出自己的 copy 角色
ThrCopy thr_copy_a = copy_a.get_slice(threadIdx.x);这句的语义是:
从整套
TiledCopy规则里,取出当前线程threadIdx.x对应的那一份局部规则。
它和 local_partition(..., threadIdx.x) 的共同点是:
- 都是根据
threadIdx.x取当前线程的数据
但区别是:
local_partition直接对 tensor 切get_slice(threadIdx.x)先从“规则对象”里取出当前线程的规则,然后再去切 tensor
这一步的目的,是把“整个 CTA 的 copy 规则”缩小到:
当前线程该怎么搬
第五步:把规则作用到 source / destination tensor 上
Tensor tAgA = thr_copy_a.partition_S(gA); // (CPY,CPY_M,CPY_K,k)
Tensor tAsA = thr_copy_a.partition_D(sA); // (CPY,CPY_M,CPY_K)
Tensor tArA = make_fragment_like(tAsA); // (CPY,CPY_M,CPY_K)这里才是真正把 tensor 切开。
partition_S 解释
partition_S(gA) 的语义是:
按照
TiledCopy规定的 source 读法,把gA这个 source tensor 切给当前线程。
partition_D 解释
partition_D(sA) 的语义是:
按照
TiledCopy规定的 destination 写法,把sA这个 destination tensor 切给当前线程。
这和 local_partition 最大的不同就在这:
local_partition只有“切”TiledCopy区分“source 怎么切”和“destination 怎么切”
因为有些硬件 copy 指令,读端和写端的模式未必相同。
具体形状
以 gA : (128, 8, k) 为例:
- 线程布局是
(32, 8) - 每个线程值布局是
(4, 1)
所以总覆盖范围是:
32 * 4 = 128,刚好覆盖 M 方向8 * 1 = 8,刚好覆盖 K 方向
因此,对当前线程来说,partition_S(gA) 的结果可以具体看成:
tAgA ≈ (4, 1, 1, k)其中:
CPY = 4:一条 copy 指令一次消费的元素组CPY_M = 1每个线程在当前这个 A tile 里,沿 M 方向只需要拿 1 组这样的包CPY_K = 1沿 K 方向也只需要拿 1 组这样的包k:外层 K tile 循环,不参与当前这次分区
对应地:
tAsA ≈ (4, 1, 1)
tArA ≈ (4, 1, 1)也就是说:
每个线程每次从 gmem 读 4 个值,先放到寄存器,再写到 smem。
本质
所以 make_tiled_copy 的本质是:
先定义 copy 指令原子,再定义线程如何重复这个原子,最后分别对 source 和 destination 做分区。
它不是单纯“线程切块”,而是:
按 copy 指令的吃法来切块。
make_tiled_mma 解释
再看这句:
TiledMMA mmaC = make_tiled_mma(
UniversalFMA<TC, TA, TB>{},
Layout<Shape<_16,_16,_1>>{}
);同样,这句也不是在切 tensor。
它只是先构造出一个“计算规则对象” mmaC。
所以你也要先记住:
make_tiled_mma(...)的输出不是某个子张量,而是一个“如何按 mma 指令去分块”的规则。
语义
make_tiled_mma(mma_atom, atom_layout) 的语义是:
先定义一个最小计算原子 mma_atom,再定义这个原子如何在 CTA 的 M/N/K 逻辑维度上重复铺开,从而形成一个 TiledMMA 分区器。这个分区器之后可以作用在 A、B、C tensor 上,得到当前线程在计算阶段该读取哪些 A/B 数据,以及负责哪些 C 累加器。
第一步:定义 mma atom
UniversalFMA<TC, TA, TB>{}它表示:
最小计算原子是一条普通的
FMA:c += a * b
所以它一次只消费:
- 1 个 A 元素
- 1 个 B 元素
- 1 个 C 元素
也就是一个 1x1x1 的 mma atom
这一步的目的,是先规定:
单条计算指令一次吃几个 A/B/C 元素
这和前面的 copy atom 完全对应,只不过一个是“搬”,一个是“算”。
第二步:定义 atom 的铺排方式
Layout<Shape<_16,_16,_1>>{}它表示:
把这个
1x1x1的计算原子,在逻辑上按16 x 16 x 1的方式重复排列。
因为 16 * 16 * 1 = 256,所以正好对应一个 block 里的 256 个线程。
这一步的目的,是规定:
哪些线程执行哪些 mma atom,以及这些 atom 在 M/N/K 上怎么铺开
它对应的,其实就是 sgemm_1 里的 tC,但这里不是简单线程布局,而是:
线程 + mma atom 的联合布局
第三步:给当前线程取出自己的 mma 角色
ThrMMA thr_mma = mma.get_slice(threadIdx.x);它的语义是:
从整套
TiledMMA规则里,取出当前线程threadIdx.x对应的那一份局部 mma 规则。
它和前面的 ThrCopy 完全平行:
ThrCopy:当前线程的 copy 规则ThrMMA:当前线程的 mma 规则
第四步:把规则作用到 A / B / C tensor 上
Tensor tCsA = thr_mma.partition_A(sA); // (MMA,MMA_M,MMA_K)
Tensor tCsB = thr_mma.partition_B(sB); // (MMA,MMA_N,MMA_K)
Tensor tCgC = thr_mma.partition_C(gC); // (MMA,MMA_M,MMA_N)
Tensor tCrC = thr_mma.make_fragment_C(tCgC);这里才是真正把 tensor 切开。
partition_A 解释
partition_A(sA) 的语义是:
按照
TiledMMA规定的 A 操作数读法,把sA切给当前线程。
partition_B 解释
partition_B(sB) 的语义是:
按照
TiledMMA规定的 B 操作数读法,把sB切给当前线程。
partition_C 解释
partition_C(gC) 的语义是:
按照
TiledMMA规定的 C 输出/累加器布局,把gC切给当前线程。
这里和 TiledCopy 的区别很明显:
TiledCopy切的是 source / destinationTiledMMA切的是 A / B / C 三种运算角色
具体形状
以 CTA tile 为:
sA : (128, 8)sB : (128, 8)gC : (128, 128)
而 TiledMMA 的 atom 布局是 (16,16,1)。
那么逻辑上:
- M 方向:
128 / 16 = 8 - N 方向:
128 / 16 = 8 - K 方向:
8 / 1 = 8
又因为 atom 本身是 1x1x1,所以第一维 MMA = 1。
于是对当前线程来说,可以把结果具体看成:
tCsA ≈ (1, 8, 8)
tCsB ≈ (1, 8, 8)
tCgC ≈ (1, 8, 8)
tCrC ≈ (1, 8, 8)也就是说:
MMA = 1:单条 FMA 指令一次只消费 1 组元素MMA_M = 8MMA_N = 8MMA_K = 8
这其实和 sgemm_1 里 tC 分出来的 (8,8) 很像,只不过现在最前面多了一层:
“单条 mma 指令的一次消费粒度”
本质
所以 make_tiled_mma 的本质是:
先定义 mma 指令原子,再定义线程如何重复这个原子,最后分别对 A/B/C 做分区。
它不是单纯“线程切块”,而是:
按 mma 指令的吃法来切块。
两者对比
make_tiled_copy | make_tiled_mma | |
|---|---|---|
| 解决的问题 | 搬运阶段如何按 copy 指令组织线程和数据 | 计算阶段如何按 mma 指令组织线程和数据 |
| 构造输入 | copy_atom + thr_layout + val_layout | mma_atom + atom_layout |
| 得到的对象 | TiledCopy 规则对象 | TiledMMA 规则对象 |
| 中间步骤 | get_slice(threadIdx.x) 得到 ThrCopy | get_slice(threadIdx.x) 得到 ThrMMA |
| 作用对象 | partition_S / partition_D | partition_A / partition_B / partition_C |
| 第一维含义 | CPY:单条 copy 指令一次消费的元素组 | MMA:单条 mma 指令一次消费的元素组 |
在 sgemm_1 中替代谁 | 替代 tA / tB + local_partition 那套搬运分区 | 替代 tC + local_partition 那套计算分区 |
| 本质 | 按搬运指令切分 | 按计算指令切分 |
make_tiled_copy / make_tiled_mma 的本质
它们不是直接替代 local_partition 这个函数本身,而是把“分区规则”升级了。
也就是:
Tensor tAgA = local_partition(gA, tA, threadIdx.x);//(THR_M,THR_K,k)
Tensor tAsA = local_partition(sA, tA, threadIdx.x);//(THR_M,THR_K)含义是:
用普通线程布局
tA切gA和sA
ThrCopy thr_copy_a = copy_a.get_slice(threadIdx.x);
Tensor tAgA = thr_copy_a.partition_S(gA);// (CPY,CPY_M,CPY_K,k)
Tensor tAsA = thr_copy_a.partition_D(sA);// (CPY,CPY_M,CPY_K)含义是:
用“copy 指令感知”的规则切
gA和sA
差别就在于:
sgemm_2多显式保留了一层CPY,表示“单条 copy 指令的一次消费组”
Tensor tCsA = local_partition(sA, tC, threadIdx.x, Step<_1, X>{});// (THR_M,BLK_K)
Tensor tCsB = local_partition(sB, tC, threadIdx.x, Step<X, _1>{});// (THR_N,BLK_K)
Tensor tCgC = local_partition(gC, tC, threadIdx.x, Step<_1, _1>{});// (THR_M,THR_N)含义是:
用普通线程布局
tC切 A/B/C
ThrMMA thr_mma = mma.get_slice(threadIdx.x);
Tensor tCsA = thr_mma.partition_A(sA);// (MMA,MMA_M,MMA_K)
Tensor tCsB = thr_mma.partition_B(sB);// (MMA,MMA_N,MMA_K)
Tensor tCgC = thr_mma.partition_C(gC);// (MMA,MMA_M,MMA_N)含义是:
用“mma 指令感知”的规则切 A/B/C
差别就在于:
sgemm_2多显式保留了一层MMA,表示“单条 mma 指令的一次消费组”
sgemm_2.cu最简实现
#include <cute/tensor.hpp>
using namespace cute;
__global__ void gemm_kernel(
int M, int N, int K,
float const* A, int ldA,
float const* B, int ldB,
float* C, int ldC,
float alpha, float beta)
{
// 1. 全尺寸 Tensor(和 sgemm_1 一样)
Tensor mA = make_tensor(make_gmem_ptr(A), make_shape(M, K), make_stride(1, ldA)); // (M,K) m-major
Tensor mB = make_tensor(make_gmem_ptr(B), make_shape(N, K), make_stride(1, ldB)); // (N,K) n-major
Tensor mC = make_tensor(make_gmem_ptr(C), make_shape(M, N), make_stride(1, ldC)); // (M,N)
// 2. CTA 分块(和 sgemm_1 一样)
auto cta_tiler = make_shape(Int<128>{}, Int<128>{}, Int<8>{}); // (BLK_M, BLK_N, BLK_K)
auto cta_coord = make_coord(blockIdx.x, blockIdx.y, _); // (m,n,k)
Tensor gA = local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{}); // (128,8,k)
Tensor gB = local_tile(mB, cta_tiler, cta_coord, Step<X, _1, _1>{}); // (128,8,k)
Tensor gC = local_tile(mC, cta_tiler, cta_coord, Step<_1, _1, X>{}); // (128,128)
// 3. SMEM 分配 + Tensor
// 为了方便和 sgemm_1 对比,这里先故意不改成 padded layout
__shared__ float smemA[128 * 8];
__shared__ float smemB[128 * 8];
Tensor sA = make_tensor(make_smem_ptr(smemA), make_layout(make_shape(Int<128>{}, Int<8>{}))); // (128,8)
Tensor sB = make_tensor(make_smem_ptr(smemB), make_layout(make_shape(Int<128>{}, Int<8>{}))); // (128,8)
// 4. 用 TiledCopy 取代 tA / tB
//
// 含义:
// - 线程仍然是 32x8 = 256 个
// - 每个线程搬 4x1 个 float
// - copy atom 规定一次按 uint128_t = 128bit 去搬,也就是 4 个 float
TiledCopy copyA = make_tiled_copy(
Copy_Atom<UniversalCopy<uint128_t>, float>{},
Layout<Shape<_32, _8>>{}, // 线程布局
Layout<Shape<_4, _1>>{}); // 每线程值布局
TiledCopy copyB = make_tiled_copy(
Copy_Atom<UniversalCopy<uint128_t>, float>{},
Layout<Shape<_32, _8>>{},
Layout<Shape<_4, _1>>{});
// 当前线程在 copyA / copyB 里的角色
ThrCopy thr_copy_a = copyA.get_slice(threadIdx.x);
ThrCopy thr_copy_b = copyB.get_slice(threadIdx.x);
// A/B 的 source / destination 分区
Tensor tAgA = thr_copy_a.partition_S(gA); // (CPY,CPY_M,CPY_K,k) = 约 (4,1,1,k)
Tensor tAsA = thr_copy_a.partition_D(sA); // (CPY,CPY_M,CPY_K) = 约 (4,1,1)
Tensor tArA = make_fragment_like(tAsA); // 寄存器 staging buffer
Tensor tBgB = thr_copy_b.partition_S(gB); // (CPY,CPY_N,CPY_K,k) = 约 (4,1,1,k)
Tensor tBsB = thr_copy_b.partition_D(sB); // (CPY,CPY_N,CPY_K) = 约 (4,1,1)
Tensor tBrB = make_fragment_like(tBsB); // 寄存器 staging buffer
// 5. 用 TiledMMA 取代 tC
//
// 这里用最简单的 UniversalFMA<float,float,float>
// 它是 1x1x1 的 mma atom
// 再铺成 16x16x1 的 TiledMMA
TiledMMA mma = make_tiled_mma(
UniversalFMA<float, float, float>{},
Layout<Shape<_16, _16, _1>>{});
ThrMMA thr_mma = mma.get_slice(threadIdx.x);
Tensor tCsA = thr_mma.partition_A(sA); // (MMA,MMA_M,MMA_K) = 约 (1,8,8)
Tensor tCsB = thr_mma.partition_B(sB); // (MMA,MMA_N,MMA_K) = 约 (1,8,8)
Tensor tCgC = thr_mma.partition_C(gC); // (MMA,MMA_M,MMA_N) = 约 (1,8,8)
// 和 sgemm_1 不同:这里不是 make_tensor_like,而是 make_fragment_C
Tensor tCrC = thr_mma.make_fragment_C(tCgC); // 寄存器累加器
clear(tCrC);
// 6. Mainloop
//
// 和 sgemm_1 最大的区别:
// 先 gmem -> rmem 预取第 0 块
copy(copyA, tAgA(_, _, _, 0), tArA);
copy(copyB, tBgB(_, _, _, 0), tBrB);
int K_TILE_MAX = size<3>(tAgA);
// 加了一个“寄存器中转层”tArA,tBrB,当前块在 smem 里计算时,下一块已经开始从 gmem 读到寄存器里了,实现搬运和计算并行
for (int k_tile = 0; k_tile < K_TILE_MAX; ++k_tile)
{
// (1) 先把“已经预取到寄存器的当前块”写进 smem
__syncthreads(); // 等上一轮所有线程都读完旧 smem
copy(tArA, tAsA); // rmem -> smem
copy(tBrB, tBsB); // rmem -> smem
__syncthreads(); // 等这一轮所有线程都写完新 smem
// (2) 同时预取下一块到寄存器
int k_tile_next = (k_tile + 1 < K_TILE_MAX) ? (k_tile + 1) : k_tile;
copy(copyA, tAgA(_, _, _, k_tile_next), tArA); // gmem -> rmem
copy(copyB, tBgB(_, _, _, k_tile_next), tBrB); // gmem -> rmem
// (3) 在 smem 上做 GEMM
gemm(mma, tCsA, tCsB, tCrC);
}
// 7. Epilogue(和 sgemm_1 一样,都是把寄存器累加器写回)
axpby(alpha, tCrC, beta, tCgC);
}
// 主机端启动
void gemm_nt(
int m, int n, int k,
float alpha,
float const* A, int ldA,
float const* B, int ldB,
float beta,
float* C, int ldC)
{
dim3 grid(ceil_div(m, 128), ceil_div(n, 128));
dim3 block(256); // 仍然是 256 线程
gemm_kernel<<<grid, block>>>(m, n, k, A, ldA, B, ldB, C, ldC, alpha, beta);
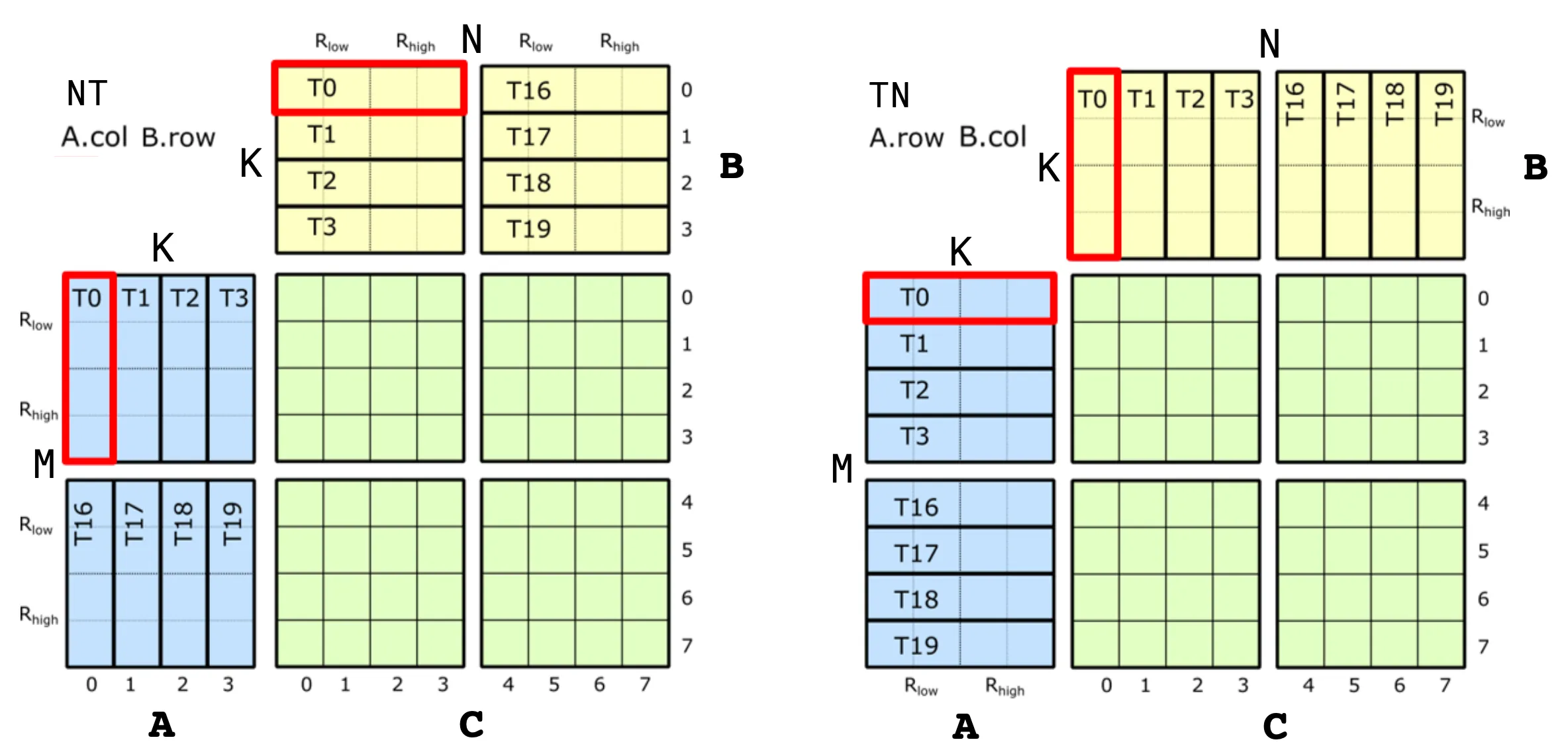
}TiledMMA 分区:A/B/C 的计算视图
这句也和 sgemm_2 一样:
ThrMMA thr_mma = mma.get_slice(threadIdx.x);
Tensor tCsA = thr_mma.partition_A(sA); // (MMA,MMA_M,MMA_K)
Tensor tCsB = thr_mma.partition_B(sB); // (MMA,MMA_N,MMA_K)
Tensor tCgC = thr_mma.partition_C(gC); // (MMA,MMA_M,MMA_N)MMA:一条 mma 指令一次消费的那组 A 元素MMA_M:当前线程负责的 M 方向那些小位置MMA_K:当前线程沿 K 方向一共有多少个“计算波次”
这里最关键的是最后一维:
MMA_K不是“元素个数”,而是“当前 tile 在 K 方向上被分成了多少个小计算波次”
Tensor tCrA = thr_mma.make_fragment_A(tCsA); // (MMA,MMA_M,MMA_K)
Tensor tCrB = thr_mma.make_fragment_B(tCsB); // (MMA,MMA_N,MMA_K)
Tensor tCrC = thr_mma.make_fragment_C(tCgC); // (MMA,MMA_M,MMA_N)- 类似地,逻辑上
tCrA在 K 维度被划分为MMA_K个 slice,每个 slice 对应一小块独立的寄存器 fragment。由于各 slice 占据互不重叠的寄存器空间,load 操作可以并行展开——在当前k_block的数据参与 MMA 计算的同时,下一份数据已被预取并写入另一个槽位k_block_next。换言之,这是在单个线程负责的 K 个 tile 基础上,将其中每个 tile 在 K 维度进一步细分为MMA_K份,通过分批预取与计算的流水线方式,实现 load 与 compute 的重叠并行。
你可以把 sgemm_sm70 的数据路径写成:
gmem -> rmem(copy staging) -> smem -> rmem(mma fragment) -> gemm -> rmem(accumulator)具体对应:
tArA/tBrB:copy staging 的寄存器sA/sB:shared memory tiletCrA/tCrB:当前计算波次的寄存器输入 fragmenttCrC:寄存器累加器
sgemm_sm70最简实现
#include <cute/tensor.hpp>
using namespace cute;
__global__ __launch_bounds__(256) void gemm_kernel_sm70(
int M, int N, int K,
float const* A, int ldA,
float const* B, int ldB,
float* C, int ldC,
float alpha, float beta)
{
// 1. 全尺寸 Tensor
Tensor mA = make_tensor(make_gmem_ptr(A), make_shape(M, K), make_stride(1, ldA)); // (M,K) m-major
Tensor mB = make_tensor(make_gmem_ptr(B), make_shape(N, K), make_stride(1, ldB)); // (N,K) n-major
Tensor mC = make_tensor(make_gmem_ptr(C), make_shape(M, N), make_stride(1, ldC)); // (M,N)
// 2. CTA 分块
auto cta_tiler = make_shape(Int<128>{}, Int<128>{}, Int<8>{}); // (BLK_M, BLK_N, BLK_K)
auto cta_coord = make_coord(blockIdx.x, blockIdx.y, _); // (m,n,k)
Tensor gA = local_tile(mA, cta_tiler, cta_coord, Step<_1, X, _1>{}); // (128,8,k)
Tensor gB = local_tile(mB, cta_tiler, cta_coord, Step<X, _1, _1>{}); // (128,8,k)
Tensor gC = local_tile(mC, cta_tiler, cta_coord, Step<_1, _1, X>{}); // (128,128)
// 3. SMEM
__shared__ float smemA[128 * 8];
__shared__ float smemB[128 * 8];
Tensor sA = make_tensor(make_smem_ptr(smemA), make_layout(make_shape(Int<128>{}, Int<8>{}))); // (128,8)
Tensor sB = make_tensor(make_smem_ptr(smemB), make_layout(make_shape(Int<128>{}, Int<8>{}))); // (128,8)
// 4. TiledCopy(NT)
TiledCopy copyA = make_tiled_copy(
Copy_Atom<UniversalCopy<uint128_t>, float>{},
Layout<Shape<_32, _8>>{}, // Thr layout 32x8 m-major
Layout<Shape<_4, _1>>{}); // Val layout 4x1 m-major
TiledCopy copyB = make_tiled_copy(
Copy_Atom<UniversalCopy<uint128_t>, float>{},
Layout<Shape<_32, _8>>{}, // Thr layout 32x8 n-major
Layout<Shape<_4, _1>>{}); // Val layout 4x1 n-major
ThrCopy thr_copy_a = copyA.get_slice(threadIdx.x);
Tensor tAgA = thr_copy_a.partition_S(gA); // (CPY,CPY_M,CPY_K,k)
Tensor tAsA = thr_copy_a.partition_D(sA); // (CPY,CPY_M,CPY_K)
Tensor tArA = make_fragment_like(tAsA); // (CPY,CPY_M,CPY_K)
ThrCopy thr_copy_b = copyB.get_slice(threadIdx.x);
Tensor tBgB = thr_copy_b.partition_S(gB); // (CPY,CPY_N,CPY_K,k)
Tensor tBsB = thr_copy_b.partition_D(sB); // (CPY,CPY_N,CPY_K)
Tensor tBrB = make_fragment_like(tBsB); // (CPY,CPY_N,CPY_K)
// 5. 先预取第 0 个 k_tile:gmem -> rmem
copy(copyA, tAgA(_, _, _, 0), tArA);
copy(copyB, tBgB(_, _, _, 0), tBrB);
// 6. TiledMMA
TiledMMA mma = make_tiled_mma(
UniversalFMA<float, float, float>{},
Layout<Shape<_16, _16, _1>>{}); // 16x16x1
ThrMMA thr_mma = mma.get_slice(threadIdx.x);
Tensor tCsA = thr_mma.partition_A(sA); // (MMA,MMA_M,MMA_K)
Tensor tCsB = thr_mma.partition_B(sB); // (MMA,MMA_N,MMA_K)
Tensor tCgC = thr_mma.partition_C(gC); // (MMA,MMA_M,MMA_N)
// 7. SM70 新增:计算输入 fragment + 累加器
Tensor tCrA = thr_mma.make_fragment_A(tCsA); // (MMA,MMA_M,MMA_K)
Tensor tCrB = thr_mma.make_fragment_B(tCsB); // (MMA,MMA_N,MMA_K)
Tensor tCrC = thr_mma.make_fragment_C(tCgC); // (MMA,MMA_M,MMA_N)
clear(tCrC);
// 8. 先把当前大块写进 smem:rmem -> smem
copy(tArA, tAsA);
copy(tBrB, tBsB);
__syncthreads();
// 9. 先加载 k_block = 0:smem -> reg(fragment)
copy(tCsA(_, _, 0), tCrA(_, _, 0));
copy(tCsB(_, _, 0), tCrB(_, _, 0));
int K_TILE_MAX = size<3>(tAgA);
int K_BLOCK_MAX = size<2>(tCrA);
// 10. PIPELINED MAIN LOOP
for (int k_tile = 0; k_tile < K_TILE_MAX; ++k_tile)
{
for (int k_block = 0; k_block < K_BLOCK_MAX; ++k_block)
{
if (k_block == K_BLOCK_MAX - 1)
{
// 这次tile快结束的时候,下一整个 k_tile:rmem -> smem
__syncthreads();
copy(tArA, tAsA);
copy(tBrB, tBsB);
__syncthreads();
}
// 下一波 k_block:smem -> reg(fragment)
int k_block_next = (k_block + 1) % K_BLOCK_MAX;
copy(tCsA(_, _, k_block_next), tCrA(_, _, k_block_next));
copy(tCsB(_, _, k_block_next), tCrB(_, _, k_block_next));
if (k_block == 0)
{
// 这次tile刚开始的时候,load下一整个 k_tile:gmem -> rmem,注意tCrA和tArA不是一块空间
int k_tile_next = (k_tile + 1 < K_TILE_MAX) ? (k_tile + 1) : k_tile;
copy(copyA, tAgA(_, _, _, k_tile_next), tArA);
copy(copyB, tBgB(_, _, _, k_tile_next), tBrB);
}
// 当前波次:reg(fragment) -> gemm
gemm(mma, tCrA(_, _, k_block), tCrB(_, _, k_block), tCrC);
}
}
// 11. Epilogue
axpby(alpha, tCrC, beta, tCgC);
}
void gemm_nt_sm70(
int m, int n, int k,
float alpha,
float const* A, int ldA,
float const* B, int ldB,
float beta,
float* C, int ldC)
{
dim3 grid(ceil_div(m, 128), ceil_div(n, 128));
dim3 block(256);
gemm_kernel_sm70<<<grid, block>>>(m, n, k, A, ldA, B, ldB, C, ldC, alpha, beta);
}对于TiledCopy和ThrCopy,对于TiledMMA和ThrCopy
关于两者,查看源码可知,其拥有的常用函数功能如下:
template <class MMA_Atom, class AtomLayoutMNK, class PermutationMNK = Tile<Underscore, Underscore, Underscore>>
struct TiledMMA : MMA_Atom
{
// ===================================================================
// get_slice / get_thread_slice
// 出发点:把 threadIdx.x 映射成 TiledMMA 内部的线程坐标 (ThrV, ThrM, ThrN, ThrK)
// 原理:使用 thr_layout_vmnk_ 把线程索引转成扁平坐标,返回一个 ThrMMA 对象
// 作用:后续所有 partition_* 都依赖这个“线程切片对象”
// 与 local_partition 的区别:这是 CuTe 推荐的现代方式,会自动生成 (thr, val) 分布
// 例子:在 sgemm_2.cu 中写 auto thr_mma = mma.get_thread_slice(threadIdx.x);
// ===================================================================
template <class ThrIdx, __CUTE_REQUIRES(is_integral<ThrIdx>::value)>
CUTE_HOST_DEVICE constexpr auto get_slice(ThrIdx const& thr_idx) const;
// get_thread_slice 和 get_slice 完全一样(只是命名习惯统一)
// 文档里两个名字都保留,是为了和 TiledCopy 写法一致
template <class ThrIdx, __CUTE_REQUIRES(is_integral<ThrIdx>::value)>
CUTE_HOST_DEVICE constexpr auto get_thread_slice(ThrIdx const& thr_idx) const;
};
template <class TiledMMA, class ThrVMNK>
struct ThrMMA : TiledMMA
{
// ===================================================================
// partition_C / partition_A / partition_B
// 出发点:把已经 tiled 的全局/共享内存 Tensor 按当前线程切成 subtensor
// 原理:内部调用 thrfrg_C/A/B(TiledMMA 的核心函数),生成 (Thr, Val) 分布
// 作用:返回该线程负责的数据视图(可直接用于 gemm / copy)
// 与 local_partition 的区别:这是真正的 (thr, val) 布局,支持任意 MMA 指令
// 例子:Tensor tCgC = thr_mma.partition_C(gC); // (MMA, MMA_M, MMA_N)
// ===================================================================
template <class CTensor>
CUTE_HOST_DEVICE constexpr auto partition_C(CTensor&& ctensor) const;
template <class ATensor>
CUTE_HOST_DEVICE constexpr auto partition_A(ATensor&& atensor) const;
template <class BTensor>
CUTE_HOST_DEVICE constexpr auto partition_B(BTensor&& btensor) const;
// ===================================================================
// partition_fragment_C / partition_fragment_A / partition_fragment_B
// 出发点:把 partition_* 返回的共享/全局视图转成寄存器 fragment
// 原理:调用 make_fragment_C/A/B(MMA_Atom 提供),生成寄存器友好的 FrgTypeC/FrgTypeA
// 作用:专门给 gemm 使用,寄存器重用最高、支持 vectorization
// 与 partition_* 的区别:一个是内存视图,一个是寄存器 fragment
// 例子:Tensor tCrC = thr_mma.partition_fragment_C(tCgC);
// ===================================================================
template <class CTensor>
CUTE_HOST_DEVICE constexpr auto partition_fragment_C(CTensor&& ctensor) const;
template <class ATensor>
CUTE_HOST_DEVICE constexpr auto partition_fragment_A(ATensor&& atensor) const;
template <class BTensor>
CUTE_HOST_DEVICE constexpr auto partition_fragment_B(BTensor&& btensor) const;
};
template <class Copy_Atom,
class LayoutCopy_TV, // (tid,vid) -> coord [Need not be 2D...]
class ShapeTiler_MN> // coord space
struct TiledCopy : Copy_Atom
{
// ===================================================================
// get_slice / get_thread_slice
// 出发点:同 TiledMMA,获取当前线程的 ThrCopy 切片对象
// 原理:把 threadIdx.x 映射到 TiledLayout_TV 的坐标
// 作用:后续 partition_S/D 和 retile 都依赖这个对象
// 例子:在 sgemm_2.cu 中写 auto thr_copy_a = copyA.get_thread_slice(threadIdx.x);
// ===================================================================
template <class ThrIdx, __CUTE_REQUIRES(is_integral<ThrIdx>::value)>
CUTE_HOST_DEVICE static auto get_slice(ThrIdx const& thr_idx);
template <class ThrIdx, __CUTE_REQUIRES(is_integral<ThrIdx>::value)>
CUTE_HOST_DEVICE static auto get_thread_slice(ThrIdx const& thr_idx);
};
template <class TiledCopy, class ThrIdx>
struct ThrCopy
{
// ===================================================================
// partition_S / partition_D
// 出发点:把全局/共享内存 Tensor 按当前线程切成 subtensor
// 原理:内部调用 tidfrg_S/D,生成 (Thr, (FrgV, FrgX), Rest...) 布局
// 作用:S = Source(读),D = Destination(写),支持 cp.async 等不同指令
// 与 local_partition 的区别:这是 CuTe 推荐的 (thr, val) 方式
// 例子:Tensor tAgA = thr_copy_a.partition_S(gA);
// ===================================================================
template <class STensor>
CUTE_HOST_DEVICE auto partition_S(STensor&& stensor) const;
template <class DTensor>
CUTE_HOST_DEVICE auto partition_D(DTensor&& dtensor) const;
// ===================================================================
// retile_S / retile_D
// 出发点:把 partition_* 返回的 (Thr, Val) 布局重排成寄存器友好形状 (Val, Thr, Rest...)
// 原理:使用 right_inverse(TiledLayout_TV) 把 Thr 模式压到后面,让 FrgV 连续
// 作用:寄存器 staging 时必须调用,支持 vectorization 和循环展开
// 什么时候用?只要要把 smem 数据拷贝到寄存器(tArA、tBrB)就必须 retile
// 与 partition_* 的区别:partition 是线程视图,retile 是寄存器视图
// 例子:Tensor tArA = ThrCopy::retile_S(tAsA);
// ===================================================================
template <class STensor>
CUTE_HOST_DEVICE static auto retile_S(STensor&& stensor);
template <class DTensor>
CUTE_HOST_DEVICE static auto retile_D(DTensor&& dtensor);
};TiledMMA 部分
1. get_slice(ThrIdx) 与 get_thread_slice(ThrIdx)
// TiledMMA::get_slice
auto thr_vmnk = thr_layout_vmnk_.get_flat_coord(thr_idx);
return ThrMMA<TiledMMA, decltype(thr_vmnk)>{*this, thr_vmnk};
// TiledMMA::get_thread_slice
return get_slice(thr_idx); // 完全相同!区别:完全一样(文档里故意写两个名字)。
get_slice是“通用”名字(后面TiledCopy也用);get_thread_slice是为了和TiledCopy保持命名一致(0x_gemm_tutorial.md里统一写thr_mma = mma.get_thread_slice(threadIdx.x))。
原理:把线程索引 threadIdx.x 映射到 TiledMMA 的内部坐标 (ThrV, ThrM, ThrN, ThrK)(thr_layout_vmnk_ 是 tiled_product(AtomThrID, AtomLayoutMNK) 生成的)。
例子(sgemm_sm70.cu):
TiledMMA mmaC = make_tiled_mma(SM70_8x8x4_F32F16F16F32_NT{}, Layout<Shape<_2,_2>>{});
auto thr_mma = mmaC.get_thread_slice(threadIdx.x); // 每个线程拿到自己的 ThrMMA 切片2. partition_C / partition_A / partition_B(ThrMMA 中的方法)
// 以 partition_C 为例(其余类似)
auto thr_tensor = make_tensor(ctensor.data(), this->thrfrg_C(ctensor.layout()));
auto thr_vmn = make_coord(get<0>(thr_vmnk_), make_coord(get<1>(thr_vmnk_), get<2>(thr_vmnk_)));
return thr_tensor(thr_vmn, make_coord(_, repeat<rank<1,1>(thr_tensor)>(_)));原理(三步):
thrfrg_C把(M,N)→((ThrV,(ThrM,ThrN)), (FrgV,(RestM,RestN)))(0t_mma_atom.md图示);- 用
thr_vmnk取出当前线程的(ThrV, ThrM, ThrN); - 返回该线程专属的 subtensor(寄存器视图)。
区别:
partition_C→ 用于累加器 C(MMA,MMA_M,MMA_N);partition_A→ 用于 A 操作数(MMA,MMA_M,MMA_K);partition_B→ 用于 B 操作数(MMA,MMA_N,MMA_K)。
例子(sgemm_2.cu):
Tensor tCsA = thr_mma.partition_A(sA); // (MMA,MMA_M,MMA_K)
Tensor tCsB = thr_mma.partition_B(sB); // (MMA,MMA_N,MMA_K)
Tensor tCgC = thr_mma.partition_C(gC); // (MMA,MMA_M,MMA_N)3. partition_fragment_C / partition_fragment_A / partition_fragment_B
template <class CTensor>
auto partition_fragment_C(CTensor&& ctensor) const
{
return TiledMMA::make_fragment_C(partition_C(ctensor));
}区别:
partition_C/A/B返回的是全局内存/共享内存视图(可读可写);partition_fragment_*返回的是寄存器 fragment(make_fragment_C内部调用MMA_Atom的DRegisters/CRegisters),专门给gemm用,寄存器重用最高效。
原理:make_fragment_C 会根据 CLayout 把 (MMA,MMA_M,MMA_N) 转成寄存器数组(例如 float[8]),避免 bank conflict。
例子(sgemm_2.cu):
Tensor tCrC = thr_mma.partition_fragment_C(tCgC); // 寄存器 fragment
cute::gemm(mma, tCsA, tCsB, tCrC); // 直接用 fragmentTiledCopy 部分
1. get_slice 与 get_thread_slice
和 MMA 完全一样(源码里 get_thread_slice 直接调用 get_slice),只是返回 ThrCopy 对象。
例子:
TiledCopy copyA = make_tiled_copy(...);
auto thr_copy_a = copyA.get_thread_slice(threadIdx.x);2. partition_S / partition_D(ThrCopy 中的方法)
// partition_S
auto thr_tensor = make_tensor(stensor.data(), TiledCopy::tidfrg_S(stensor.layout()));
return thr_tensor(thr_idx_, _, repeat<rank_v<STensor>>(_));
// partition_D 同理,用 tidfrg_D原理(与 MMA 类似,但有 Src/Dst 区别):
tidfrg_S使用AtomLayoutSrc把(M,N)→(Thr,(FrgV,FrgX),(RestM,RestN));tidfrg_D使用AtomLayoutDst(可能和 Src 不同,例如 TMA 要求 Src 是 gmem、Dst 是 smem);partition_S返回 source tensor 的线程视图;partition_D返回 destination tensor 的线程视图。
区别:S = Source(读),D = Destination(写)。
这是因为 Copy_Atom 里 ValLayoutSrc 和 ValLayoutDst 可以不一样(UniversalCopy 相同,cp.async 不同)。
例子(sgemm_2.cu):
Tensor tAgA = thr_copy_a.partition_S(gA); // source(gmem)
Tensor tAsA = thr_copy_a.partition_D(sA); // dest(smem)
cute::copy(copyA, tAgA, tAsA);3. retile_S / retile_D(静态方法)
// 两者完全相同(源码里 retile 是静态的)
auto frg_layout_v = ...; // 把 (ThrV, FrgV) 转成寄存器友好的布局,原来的布局是线程优先(Thr, (FrgV, FrgX), Rest...)
//retile 把它翻转成值优先(FrgV, (Thr, FrgX), Rest...),方便读取
return make_tensor(tensor.data(), TiledCopy::retile(tensor.layout()));区别:无区别(只是为了命名对称)。
retile 是寄存器重排操作,把 (Thr, Val) 转成 (Val, Rest),方便寄存器循环展开和 vectorization。
原理:retile 用 upcast + right_inverse(TiledLayout_TV) 把线程布局“压平”,让每个线程的 FrgV 连续存储。
例子:
Tensor tArA = ThrCopy::retile_S(tAsA); // 把 smem 视图转成寄存器连续布局
copy(copyA, tAgA, tArA);下面是只修正有问题的描述后的版本,结构不变。
和local_tile 、 local_partition的区别
local_tile 和 local_partition 本身并不直接引入 Copy/MMA 指令语义下的 (thr, val) 分布。
它们只是通用切片工具:
local_tile=inner_partition,可理解为zipped_divide之后切 Rest 模式、保留 Tile 模式(常给 CTA / threadgroup 用)local_partition= 一个 rank-sensitive 的outer_partition封装,本质上是先根据Layout + Idx生成对应的Coord/Tiler,再对zipped_divide的结果切 Tile 模式、保留 Rest 模式(常给线程用)
它们不会自动引入 CopyAtom / MMAAtom 那种“单条指令吃几个值”的语义,也不会自动生成 FrgV 这一层。
真正产生 (thr, val) 分布的函数
只有下面这些函数才会在 TiledCopy / TiledMMA 这套语义里,把普通 tensor 重新解释成带线程-值分工的布局:
| 函数 | 所属对象 | 产生的布局结构 | 文档出处 |
|---|---|---|---|
thrfrg_C / thrfrg_A / thrfrg_B | TiledMMA | ((ThrV, (ThrM, ThrN)), (FrgV, ...)) | 0t_mma_atom.md |
tidfrg_S / tidfrg_D | TiledCopy | (Thr, (FrgV, FrgX), ...) | TiledCopy 源码 |
partition_C / partition_A / partition_B | ThrMMA | 内部先用 thrfrg_* 构造线程-值布局,再按当前线程切片 | 0x_gemm_tutorial.md |
partition_S / partition_D | ThrCopy | 内部先用 tidfrg_* 构造线程-值布局,再按当前线程切片 | sgemm_2.cu |
get_layoutC_TV 等 | TiledMMA/Copy | 返回纯 (thr, val) → coord 映射,本身不是对某个 tensor 做切片 | 0t_mma_atom.md |
这些才是 CuTe 里面带有 Copy/MMA 指令分工语义的现代写法。
sgemm_1.cu vs sgemm_2.cu 对比(最直观)
sgemm_1.cu(老式,手动):
auto tC = make_layout(Shape<_16,_16>{});
Tensor tCgC = local_partition(gC, tC, threadIdx.x, Step<_1,_1>{});
Tensor tCrC = make_tensor_like(tCgC); // 手动
cute::gemm(tCsA, tCsB, tCrC); // 只能用 UniversalFMAsgemm_2.cu(现代,推荐):
TiledMMA mma = make_tiled_mma(UniversalFMA<...>{}, Layout<Shape<_16,_16,_1>>{});
auto thr_mma = mma.get_thread_slice(threadIdx.x);
Tensor tCgC = thr_mma.partition_C(gC); // ← 内部先用 thrfrg_C 构造布局,再切当前线程
Tensor tCrC = thr_mma.partition_fragment_C(tCgC); // ← 进一步得到适合 MMA 的 fragment
cute::gemm(mma, tCsA, tCsB, tCrC);区别:
local_partition:通用线程切片工具,没有 Copy/MMA 指令内部的FrgV、ThrV、AtomLayout_TV这些专门语义。thr_mma.partition_*:会按照TiledMMA的规则自动建立线程-值分工,因此能直接适配任意 MMA 指令(Volta/Hopper 等)。
CuTe TMA Tensor 深度解析
1. 发明背景:TMA 指令为什么需要新的 Tensor 类型
要理解 TMA Tensor 为什么被发明,必须先搞清楚 TMA 指令的本质与普通 CUDA 内存操作的根本区别。
1.1 普通 CUDA 内存操作的工作方式
在传统 CUDA kernel 中,数据搬运是以线程为单位进行的:每条线程自己算出要读/写的元素地址,发出 load/store 指令。CuTe 的普通 Tensor 正是为这种模式量身定制的:
// 普通 CuTe Tensor 的工作模式
Tensor gmem_tensor = make_tensor(ptr, make_shape(M, N), make_stride(1, M));
// 访问 (i, j) 处的元素:
// layout 计算线性 offset -> i*1 + j*M
// iterator 前进该 offset -> ptr + i*1 + j*M
// 最终取得 GMEM 上的真实指针这整套流程的核心是:逻辑坐标 → 线性地址偏移 → 真实指针。
1.2 TMA 指令的工作方式截然不同
TMA(Tensor Memory Accelerator)是 Hopper(SM90)架构上的一组硬件指令,专门负责在 Global Memory 和 Shared Memory 之间高效搬运整块 tile 数据,不再需要每个线程逐元素发指令。
TMA 的关键在于它依赖一个提前在 host 端构造好的 TMA descriptor。这个 descriptor 是一个打包好的描述符,里面包含:
- GMEM 基地址(数组起始指针)
- 元素数据类型(如 fp16、bf16、float 等)
- 各维度大小(shape)
- 各维度 stride(步长)
- Shared Memory 侧的 box 大小(每次搬多大的 tile)
- Swizzle 模式(内存访问优化)
- 越界行为(Out-of-bound 处理策略)
真正在 kernel 中执行 TMA 指令时,你给它的参数是:descriptor 指针、smem 指针、以及 GMEM 视角下的多维坐标。
⚠️ 关键区别:TMA 指令不接受 GMEM pointer!
它接受的是「多维坐标」(例如在一个 128×64 的矩阵里,坐标是
(row, col)),再配合 descriptor 里已经存好的基地址和 stride,由硬件自己算出最终地址并完成搬运。
1.3 矛盾在哪里
这就产生了一个根本矛盾:
| 维度 | 普通 CuTe Tensor | TMA 需要的 |
|---|---|---|
| 存储内容 | GMEM 指针 | 不需要 GMEM 指针 |
| layout 输出 | 线性地址偏移(整数) | 多维坐标(tuple) |
| 最终传给指令 | 真实内存地址 | 坐标 + descriptor |
| 适合的访问模式 | per-thread 逐元素访问 | 整 tile 批量搬运 |
简言之:普通 CuTe Tensor 对 TMA 来说是没用的——它输出的是线性地址,而 TMA 根本不吃这个。所以 CuTe 必须发明一种新的 Tensor,使其能直接输出 TMA 所需的多维坐标。这就是本文档的全部目的。
2. 第一步过渡:Tensor 的迭代器不一定是指针
在直接引入 TMA Tensor 之前,文档先做了一个思想热身——打破「Tensor 一定绑定真实内存」的固有印象。
2.1 CuTe Tensor 的本质结构
CuTe Tensor 从设计上看,其实是两个部分的组合:
- Layout:描述「逻辑坐标如何映射到某个 index」的规则
- Iterator(迭代器):一个可以被 index 的「数据源」
普通 GMEM Tensor 的 iterator 是一个真实的 GPU 指针,index 它就能得到内存里的元素。但 iterator 的本质要求并不是「必须是指针」,而只需要满足:「能被 layout 计算出的 index 偏移,得到某个结果」。
2.2 counting_iterator 的例子
文档用 counting_iterator 作为第一个热身例子:
Tensor A = make_tensor(counting_iterator<int>(42), make_shape(4,5));
// 打印结果:
// counting_iter(42) o (4,5):(_1,4):
// 42 46 50 54 58
// 43 47 51 55 59
// 44 48 52 56 60
// 45 49 53 57 61这个 Tensor 没有任何真实内存。它的含义是:
- iterator 的「起点」是整数 42
- layout 是
(4,5):(1,4),意思是行方向步长 1,列方向步长 4 - 对逻辑坐标
(i,j)应用 layout,得到offset = i*1 + j*4 - iterator 被偏移后,就是
42 + offset
所以 Tensor[1][2] = 42 + 1 + 2*4 = 51。这个值不是从内存里读来的,而是「根据规则现算出来的」。
📌 这一步的意义
证明了:CuTe Tensor 的 data 部分不一定是真实内存,也可以是「隐式生成的值」。最重要的是,这种 Tensor 仍然可以像普通 Tensor 一样被 tile、partition、slice——CuTe 的整套工具链对它完全适用。这为后续推广到「坐标 Tensor」铺平了道路。
3. 第二步过渡:从「生成整数」到「生成坐标」
文档接着问了一个关键问题:
🤔
counting_iterator能生成「整数」;那我们能不能造一个类似的东西,让它生成「TMA 坐标」?如果可以,那对这个「坐标 Tensor」做 tile/partition/slice,得到的就是每个分块对应的 TMA 坐标——可以直接喂给 TMA 指令,完全不需要额外计算。
这就是整篇文档的核心主线,所有后续的机制都是为了实现这一点而引入的。
| 维度 | 普通 Tensor | TMA Tensor(目标) |
|---|---|---|
| iterator 里存的 | GMEM 指针 | 当前 TMA 坐标 |
| layout 输出 | 线性 offset(整数) | TMA 坐标增量(tuple) |
| 最终结果 | 指向某元素的地址 | 能传给 TMA 的多维坐标 |
| 对 tile/partition 的支持 | ✅ | ✅(目标) |
4. 构造坐标迭代器:ArithmeticTuple 与 ArithmeticTupleIterator
4.1 ArithmeticTuple 是什么
普通的 tuple 只是一个「容器」,把几个值装在一起。ArithmeticTuple 在此基础上额外实现了代数运算——最关键的是 operator+,使得两个 tuple 可以逐元素相加:
// 概念示意
ArithmeticTuple a = (42, 2, 7);
ArithmeticTuple b = (0, 5, 2);
ArithmeticTuple c = a + b; // -> (42, 7, 9)
// 普通 tuple 不支持 + 操作;
// ArithmeticTuple 支持,且按位(逐元素)相加。4.2 ArithmeticTupleIterator 是什么
ArithmeticTupleIterator 就是「counting_iterator 的坐标版本」:
counting_iterator内部存着一个整数,解引用得到这个整数,偏移时整数增加ArithmeticTupleIterator内部存着一个ArithmeticTuple(坐标),解引用得到这个坐标,偏移时坐标按 tuple 加法更新
文档给出的例子:
ArithmeticTupleIterator citer_1 = make_inttuple_iter(42, Int<2>{}, Int<7>{});
// citer_1 内部存着坐标:(42, 2, 7)
ArithmeticTupleIterator citer_2 = citer_1 + make_tuple(Int<0>{}, 5, Int<2>{});
// 做的事情:(42, 2, 7) + (0, 5, 2) = (42, 7, 9)
print(*citer_2);
// 输出:(42,7,_9)
// (带下划线的是编译期常量,不带的是运行期值)注意这里的「偏移」不是「指针移动了多少字节」,而是「坐标移动到了哪里」。这就是从「寻址模式」到「坐标模式」的本质转变。
4.3 make_inttuple_iter 的实际含义
调用 make_inttuple_iter(a, b, c, ...) 就是创建一个 ArithmeticTupleIterator,其内部起始坐标是 (a, b, c, ...)。在构造 TMA Tensor 时,通常用 make_inttuple_iter(0, 0) 表示从坐标原点 (0, 0) 开始。
5. 最核心的思想跃迁:Stride 不一定是整数
这是整篇文档最关键的一步,也是 TMA Tensor 能够成立的根本原因。
5.1 普通 Layout 的工作原理回顾
// 逻辑坐标 (i, j),stride (s0, s1)
// layout 计算:i*s0 + j*s1
// 例:stride = (1, 100)
// (i, j) -> i*1 + j*100 <-- 这是一个整数
// 这个整数用来 offset 指针:ptr + (i + 100*j)整个过程产出「整数 offset」,这很合理——因为指针只能用整数偏移。
5.2 如果 Stride 不是整数,会发生什么
文档提出的核心洞察:Layout 的内积计算,它的数学公式是不变的。变的只是 stride 的类型。如果 stride 不是整数,而是某种「可与整数相乘、多个可以相加」的对象,那内积的结果就不再是整数,而是那种对象的线性组合。
💡 思想跃迁的关键
stride 的类型要求不是「必须是整数」,而是:
- 支持「与整数相乘」(scalar multiplication)
- 支持「多个 stride 贡献值相加」(addition)
满足这两点,Layout 就能在形式不变的情况下,把输出从「整数」变成「坐标」。
5.3 如果 Stride 换成坐标方向基向量
如果把 stride 换成坐标空间里的基向量 (1@0, 1@1)(稍后解释这个符号的含义),那么内积结果就是:
// stride = (1@0, 1@1),代表两个坐标方向
// 逻辑坐标 (i, j) 的 layout 内积:
// i * (1@0) + j * (1@1)
// = i@0 + j@1
// = (i, j) <-- 这是一个二维坐标!
// 如果把 stride 交换为 (1@1, 1@0):
// i * (1@1) + j * (1@0)
// = i@1 + j@0
// = (j, i) <-- 坐标的行列顺序对调了这个结论意义重大:通过设计 stride,我们可以控制「逻辑坐标怎样映射到 TMA 坐标」。这与普通 Tensor 里「通过 stride 控制线性地址排列」的思想完全类似,只不过输出从整数变成了多维坐标。
6. Basis Element:坐标空间中的单位基向量
为了表达「坐标方向」,CuTe 引入了 Basis Element,用 E<...>{} 语法表示。这是让 stride 能产出坐标的核心工具。
6.1 最简单的情形:一维基向量
E<>{} // 普通的 1(退化为整数,与普通 stride 行为相同)
E<0>{} // 打印为 1@0,表示沿第 0 个坐标轴方向走 1
E<1>{} // 打印为 1@1,表示沿第 1 个坐标轴方向走 1
E<2>{} // 打印为 1@2,表示沿第 2 个坐标轴方向走 1可以把它们类比为标准基向量:
| Basis Element | 类比的直觉理解 |
|---|---|
E<0>{} = 1@0 | 类似二维向量 (1, 0),沿第 0 维走 1 |
E<1>{} = 1@1 | 类似二维向量 (0, 1),沿第 1 维走 1 |
E<2>{} = 1@2 | 类似三维向量 (0, 0, 1),沿第 2 维走 1 |
6.2 Scaled Basis:乘以整数系数
基向量可以与整数相乘,表示在该方向上走更大的步长:
5 * E<0>{} // 打印为 5@0,沿第 0 维走 5
5 * E<1>{} // 打印为 5@1,沿第 1 维走 5
64 * E<1>{} // 打印为 64@1,沿第 1 维走 64
// 联系到普通 stride:
// 普通整数 stride=5 表示「线性地址每次增 5」
// 5@1 表示「TMA 坐标第 1 维每次增 5」6.3 Nested Basis:嵌套坐标方向
Basis element 还可以嵌套,以适配层次化的 TMA 坐标:
E<0,1>{} // 打印为 1@1@0
// 含义:在第 0 层坐标的第 1 个子分量方向走 1
E<1,0>{} // 打印为 1@0@1
// 含义:在第 1 层坐标的第 0 个子分量方向走 1
5 * E<0,1>{} // 打印为 5@1@0
// 含义:在那个嵌套方向走 5嵌套结构的意义在于:TMA 坐标本身可以是多层次的(比如 mode 0 本身就是一个 tuple)。Nested basis element 就是为了对应这种结构而设计的。
6.4 线性组合:多个基向量相加
多个 basis element 可以线性组合,产出一个复合坐标:
// 示例:多项相加
result = 2*(2@1@0) + 3*(1@1) + 4*(5@1) + 7*(1@0@0)
= 4@1@0 + 3@1 + 20@1 + 7@0@0
= ((7, 4), 23) // 最终拼出一个两层嵌套坐标
// 解读:
// 7@0@0 -> 外层第 0 分量里的第 0 子分量加 7
// 4@1@0 -> 外层第 0 分量里的第 1 子分量加 4
// 3@1 -> 外层第 1 分量加 3
// 20@1 -> 外层第 1 分量再加 20,共加 23这说明:Basis element 的线性组合,可以构造出任意层次、任意分量的复杂 TMA 坐标。这正是 Layout 内积运算的输出——不再是一个整数,而是一个完整的多维坐标对象。
7. 构造真正的 TMA Tensor:完整例子详解
现在所有组件都齐了,来看文档里最终给出的两个完整 TMA Tensor 例子:
7.1 例子 a:标准映射
Tensor a = make_tensor(
make_inttuple_iter(0, 0), // iterator 原点:坐标 (0,0)
make_shape(4, 5), // 逻辑 shape:4行 5列
make_stride(E<0>{}, E<1>{})); // stride:(1@0, 1@1)
// 逻辑坐标 (i,j) 的映射:
// i*(1@0) + j*(1@1) = (i, j) <-- 直接就是 TMA 坐标 (i,j)
// 打印结果:
// (0,0) (0,1) (0,2) (0,3) (0,4)
// (1,0) (1,1) (1,2) (1,3) (1,4)
// (2,0) (2,1) (2,2) (2,3) (2,4)
// (3,0) (3,1) (3,2) (3,3) (3,4)这个 Tensor 的每个「元素」不是真实数据,而是「应该传给 TMA 的坐标」。对它切 tile 或 partition,得到的就是对应分块的 TMA 坐标。
7.2 例子 b:坐标轴对调
Tensor b = make_tensor(
make_inttuple_iter(0, 0),
make_shape(4, 5),
make_stride(E<1>{}, E<0>{})); // stride 交换:(1@1, 1@0)
// 逻辑坐标 (i,j) 的映射:
// i*(1@1) + j*(1@0) = (j, i) <-- TMA 坐标变成 (j,i),行列互换
// 打印结果:
// (0,0) (1,0) (2,0) (3,0) (4,0)
// (0,1) (1,1) (2,1) (3,1) (4,1)
// (0,2) (1,2) (2,2) (3,2) (4,2)
// (0,3) (1,3) (2,3) (3,3) (4,3)逻辑上的「行列顺序」没变——还是 4×5 的 tensor。但每个位置对应的 TMA 坐标里行列对调了。这完全类比于普通 Tensor 里「通过 stride 控制行优先/列优先」的做法。
8. 逐项解读那串「最吓人的打印」
文档里出现的这串打印是整篇文章最吓人的地方:
ArithTuple(0,_0,_0,_0) o ((_128,_64),2,3,1):((_1@0,_1@1),_64@1,_1@2,_1@3)现在逐项翻译:
8.1 ArithTuple(0,_0,_0,_0)
这是 Tensor 的 iterator 当前值,即「坐标原点」:
- 不是指针,不是内存地址
- 是一个 4 层的
ArithmeticTuple坐标 - 带下划线的
_0表示编译期常量 0;不带的0是运行期值 0 - 整体理解:从
(0, 0, 0, 0)这个坐标原点出发
8.2 o(小写字母 o)
这个符号是 CuTe 的标准打印格式,表示:iterator o layout,即「这个 Tensor = 某迭代器 + 某布局」。
8.3 ((_128,_64),2,3,1) — Shape
这是 Tensor 的逻辑 shape,它是分层的:
- 最外层有 4 个 mode
- 第 0 个 mode 本身是一个嵌套 tuple:
(_128, _64),意思是这个 mode 内部还分两层,大小分别是 128 和 64 - 第 1 个 mode 大小是 2
- 第 2 个 mode 大小是 3
- 第 3 个 mode 大小是 1
整个逻辑空间的总元素数 = 128 × 64 × 2 × 3 × 1 = 49152。
8.4 ((_1@0,_1@1),_64@1,_1@2,_1@3) — Stride
这是 stride,每一项都是 basis element,不是整数。对应 shape 的每一个 mode:
| Shape Mode | Stride | 含义 |
|---|---|---|
(_128,_64) 内的 128 | _1@0 | 沿第 0 个 TMA 坐标维度走 1 |
(_128,_64) 内的 64 | _1@1 | 沿第 1 个 TMA 坐标维度走 1 |
| 2 | _64@1 | 沿第 1 个 TMA 坐标维度走 64 |
| 3 | _1@2 | 沿第 2 个 TMA 坐标维度走 1 |
| 1 | _1@3 | 沿第 3 个 TMA 坐标维度走 1 |
直观理解这串 stride:
- 在 mode 0 内部,每沿「第 0 子维度」走 1 步,TMA 坐标第 0 分量 +1
- 在 mode 0 内部,每沿「第 1 子维度」走 1 步,TMA 坐标第 1 分量 +1
- 在 mode 1,每走 1 步,TMA 坐标第 1 分量 +64(即在第 1 维跨越 64 的跨度)
- 在 mode 2,每走 1 步,TMA 坐标第 2 分量 +1
- 在 mode 3(大小为 1),永远只有一个位置,TMA 坐标第 3 分量 +1(实际不动)
整串打印真正的含义不是「这个 Tensor 在显存里怎么排布」,而是:「这个 Tensor 的逻辑坐标,会被翻译成什么样的 TMA 多维坐标」。
9. 为什么 CuTe 原有工具链可以直接复用
TMA Tensor 的最大设计亮点,是它与 CuTe 原有的 tile/partition/slice 体系完全兼容。
9.1 CuTe 工具链对 Tensor 的唯一要求
tile、partition、slice 等操作的实现,其实只依赖于:
- Tensor 有一个 shape(决定了逻辑坐标空间)
- Tensor 有一个 layout(决定了坐标如何映射)
- Layout 的 stride 能做整数乘法和相加
TMA Tensor 满足这三条——只是 stride 的类型从整数换成了 basis element,但 basis element 完全支持「与整数相乘」和「相加」(这正是它被专门设计成这样的原因)。
9.2 切 tile 的结果
// 对 TMA Tensor 切 tile
Tensor tma_tensor = make_tensor(make_inttuple_iter(0,0,0),
make_shape(M, N, K),
make_stride(E<0>{}, E<1>{}, E<2>{}));
// 切出 (tile_m, tile_n) 大小的 tile
auto tile = local_tile(tma_tensor, make_shape(tile_m, tile_n), ...);
// tile 仍然是一个 TMA Tensor
// 访问 tile 的任一元素,得到的是该元素对应的 TMA 坐标
// 直接传给 TMA copy 指令即可9.3 一个具体的 kernel 场景
在 Hopper 上写 GEMM kernel 时,通常的完整流程是:
- Host 端:为矩阵 A、B 建好 TMA descriptor
- Host 端:构造对应的 TMA Tensor(坐标 Tensor),描述整个 GMEM 的逻辑结构
- Kernel 端:通过 CTA tile 划分,得到每个 CTA 对应的 TMA Tensor 分块
- Kernel 端:从分块 TMA Tensor 里取到「该 CTA 应该搬运的 tile 的 TMA 坐标」
- Kernel 端:用这个坐标 + descriptor + smem pointer 发 TMA load/store 指令
整个过程里,CTA 之间的划分、warpgroup 之间的数据分配,全部复用普通 CuTe 的 tile/partition 工具,没有任何额外的坐标计算逻辑需要手写。
你说得对,过度使用修辞确实会掩盖技术本身的清晰度,尤其是在讨论底层硬件和位运算时,我们需要的是绝对的严谨和直白。我们直接去掉所有花哨的比喻,回归到最朴素的工程逻辑、数学公式和具体的位运算步骤上。
下面是一份完全基于硬件数据、计算公式和代码逻辑的 Swizzle<B, M, S> 详细技术说明。
Swizzle 的基本工作原理
Swizzle 的实质是对一维内存索引(Index)进行位运算(异或,XOR),从而改变数据在物理内存中的存放位置。
它的目的只有一个:当多线程以非连续的跨度(Stride)读取内存时,避免多个请求落入同一个 Shared Memory Bank(引发 Bank Conflict),同时还要保证 128-bit(16 Bytes)向量化读取的内存连续性。
其内部运算逻辑伪代码如下:
C++
// idx 为逻辑元素索引
int target_bits = (idx >> M) & ((1 << B) - 1); // 提取准备被替换的低位
int control_bits = (idx >> (M + S)) & ((1 << B) - 1); // 提取用于触发异或的高位
int xor_result = target_bits ^ control_bits; // 执行异或
// 最终将 idx 中的 target_bits 替换为 xor_result 得到物理索引三个模板参数 <B, M, S> 的严格定义与计算方法
为了计算这三个参数,我们必须基于以下两个不变的硬件物理常量:
- 物理行宽:Shared Memory 有 32 个 Bank,每个 Bank 宽 4 Bytes,一整行的物理宽度固定为 128 Bytes。
- 向量化读取要求:为了达到峰值带宽,GPU 采用 128-bit 的向量化加载指令。这要求内存中连续的 16 Bytes 绝对不能被任何机制打乱。
1. 参数 M (MBase):保留不参与异或的低位个数
定义:从第 0 位开始,有 M 个比特位不参与异或运算,原样保留。
计算目标:保证连续的 16 Bytes 在物理内存中依然是连续的。
推导与计算步骤:
因为 CuTe 中传入的索引是元素索引(Element Index),所以我们需要算出 16 Bytes 能装下多少个该类型的元素,并求其以 2 为底的对数。
-
公式: $$ M = \log_2 \left( \frac{16}{\text{sizeof(DataType)}} \right) $$
-
具体计算演示:
-
如果是 FP16 (半精度浮点数,占 2 Bytes):
16 Bytes 可以容纳 16 / 2 = 8个 FP16 元素。
为了表示这连续的 8 个元素,我们需要 3 个比特位(因为 2^3 = 8)。
结论:此时 M = 3。即使用
Swizzle<B, 3, S>。 -
如果是 FP32 (单精度浮点数,占 4 Bytes):
16 Bytes 可以容纳 16 / 4 = 4 个 FP32 元素。
为了表示这连续的 4 个元素,我们需要 2 个比特位(因为 2^2 = 4)。
结论:此时 M = 2。即使用
Swizzle<B, 2, S>。 -
如果是 FP8 (8位浮点数,占 1 Byte):
16 Bytes 可以容纳 16 / 1 = 16 个 FP8 元素。
表示 16 个元素需要 4 个比特位(因为 2^4 = 16)。
结论:此时 M = 4。即使用
Swizzle<B, 4, S>。
-
2. 参数 B (BBits):参与异或运算的比特位个数
定义:提取多少个比特位进行 XOR 计算。这决定了内存行被切分为多少个独立的交错块。
计算目标:完整覆盖 128 Bytes 的物理行。
推导与计算步骤:
-
公式: $$ B = \log_2 \left( \frac{\text{物理行总字节数}}{\text{连续保留字节数}} \right) $$
-
具体计算:
物理行总字节数 = 128 Bytes。
连续保留字节数 = 16 Bytes。
一行中包含的块数 = 128 / 16 = 8 个块。
为了对这 8 个块进行编号和异或打乱,我们需要 \log_2(8) = 3 个比特位。
-
结论:在标准架构下,B 永远固定等于 3。
3. 参数 S (SShift):控制位的左移偏移量
定义:控制高位是从低位起点(M)再向左移动 S 位提取的。
计算目标:确保只有当内存地址跨越了一整行(128 Bytes)时,才触发一次异或模式的改变。
推导与计算步骤:
我们需要对比“基本块边界”和“物理行边界”在二进制位上的差异。
-
基本块大小是 16 Bytes(即 2^4 Bytes),其对应的位是第 4 位。
-
物理行大小是 128 Bytes(即 2^7 Bytes),跨越一行的标志位是第 7 位。
-
公式:
S = \text{行边界位} - \text{块边界位}
-
具体计算:S = 7 - 4 = 3。
-
结论:为了精准捕获换行操作,S 永远固定等于 3。
明确的使用场景判断
在工程中,是否引入 Swizzle 并不取决于“是不是矩阵”,而是取决于数据的读写步长(Stride)特征。
1. 应当使用 Swizzle 的场景
- 矩阵乘法(GEMM)中的 Shared Memory:Tensor Core(MMA 指令)要求以特定的交错模式从 Shared Memory 读取 A 矩阵和 B 矩阵。这必然包含非连续的跨步读取。这是
Swizzle最核心的应用点。 - Shared Memory 内的矩阵转置:写入时是连续的行(Stride=1),读出时是跳跃的列(Stride=矩阵宽度)。列向读取会导致严重的 Bank Conflict,必须用
Swizzle打乱。 - 算法中存在 2 的幂次方跨度访问:如并行规约(Reduction)或快速傅里叶变换(FFT),循环中存在跳跃步长为 8, 16, 32 的内存访问。
2. 不应使用 Swizzle 的场景
- 一维连续访问:如果数据写入和读出都是按照
idx = 0, 1, 2, 3...连续进行的,此时硬件天然无 Bank Conflict,引入Swizzle是徒增指令开销。 - 数据结构未对齐:如果数据不是以 2 的幂次方对齐的,或者矩阵的内部连续维度(Leading Dimension)小于 128 Bytes,
Swizzle的按位异或将无法正确对齐到 Bank 边界,不仅起不到作用,还可能引发额外的访存延迟。 - 全 Warp 读取同一个标量:多个线程读取 Shared Memory 中的同一个地址,硬件会触发 Broadcast(广播),这是最高效的访问方式,不需要打乱。
| 矩阵行号 (高位) | 第 0 列 | 第 1 列 | 第 2 列 | 第 3 列 |
|---|---|---|---|---|
| Row 0 | Bank 0 | Bank 1 | Bank 2 | Bank 3 |
| Row 1 | Bank 1 | Bank 0 | Bank 3 | Bank 2 |
| Row 2 | Bank 2 | Bank 3 | Bank 0 | Bank 1 |
| Row 3 | Bank 3 | Bank 2 | Bank 1 | Bank 0 |
经过正确Swizzle的矩阵可以实现行列读取都不导致bank conflict
Tensor Core mma 硬件级空间切分与数据交织法则
详细的各个架构mma的不同布局详见:
一、 核心发现 (The Core Discovery)
在执行底层的 mma.m8n8k4(矩阵乘加)指令时,Warp 内 32 个线程对操作数(矩阵 A 和 B)的读取与分配,并非基于随意的软件逻辑,而是严格遵循基于 Half-Warp(半线程束)的物理空间对称切分契约。
结论陈述:
对于输入矩阵,硬件沿着进行乘法运算的核心维度(矩阵 A 的 M 维度,矩阵 B 的 N 维度),将其强行“腰斩”为上下/左右两半。
- 前半个 Warp (代表线程
%laneid 0~3):绝对绑定并锁定目标维度的上半区/左半区。 - 后半个 Warp (代表线程
%laneid 16~19):绝对绑定并锁定目标维度的下半区/右半区。
无论数据在内存中是 Row-Major(行主序)还是 Column-Major(列主序),这个基于物理线程 ID 的空间维度分配法则坚如磐石。
二、 深度推导与逻辑拆解:输入端的三维映射
为了证明这一发现的普适性,我们将矩阵 $C = A \times B$ 的输入端拆解如下:
1. 矩阵 A ($8 \times 4$):M 维度(行)的绝对切分
在 $M \times K$ 的坐标系中,$K$ 维度的数据由单线程内部的寄存器组合(如 V0, V1, V2, V3)横向/纵向吞吐。Warp 分组唯一能切分的空间是 M 维度(行)。
| 物理线程组 | 逻辑角色 | 掌管的 M 维度空间 | 对应寄存器行为 (以列主序为例) |
|---|---|---|---|
| T0 - T3 | 低组 (Lower Half-Warp) | 上半区 ($M = 0 \dots 3$) | T0 吞吐第 0 列的 $M_0 \sim M_3$ |
| T16 - T19 | 高组 (Upper Half-Warp) | 下半区 ($M = 4 \dots 7$) | T16 吞吐第 0 列的 $M_4 \sim M_7$ |
2. 矩阵 B ($4 \times 8$):N 维度(列)的绝对切分
视角切换到 $K \times N$ 坐标系,$K$ 维度依然由内部寄存器消化,此时切分刀刃转向了 N 维度(列)。
| 物理线程组 | 逻辑角色 | 掌管的 N 维度空间 | 对应寄存器行为 (以行主序为例) |
|---|---|---|---|
| T0 - T3 | 低组 (Lower Half-Warp) | 左半区 ($N = 0 \dots 3$) | T0 吞吐第 0 行的 $N_0 \sim N_3$ |
| T16 - T19 | 高组 (Upper Half-Warp) | 右半区 ($N = 4 \dots 7$) | T16 吞吐第 0 行的 $N_4 \sim N_7$ |
三、 反直觉陷阱:输出端 C 矩阵 ($8 \times 8$) 的二维纠缠
切记:输入端的“完美对称切分”在输出端会瞬间失效。 不能用输入端 $M/N$ 的直觉去推导累加器(Accumulator)的结果分布。
- 直觉谬误:既然 T0 拿了 $M$ 的上半区和 $N$ 的左半区,那 T0 算出来的结果应该是一个完美的 $4 \times 4$ 左上角矩阵。
- 物理现实:Tensor Core 内部署了复杂的交叉路由(Crossbar Routing)。因为矩阵乘法的本质是“A 的每一行都要与 B 的每一列相乘”。
推导过程(以 T0 为例):
- T0 握有 $M=0$ 的数据。
- 在计算瞬间,硬件不仅让 T0 用自己的 $M=0$ 乘以自己手里的 $N=0 \sim 3$(左半区)。
- 硬件的 Crossbar 会把 T16 手里的 $N=4 \sim 7$(右半区)数据硬连线广播 (Broadcast) 给 T0。
- 因此,T0 最终计算出的 8 个元素,被打碎并散落在第一象限和第二象限的离散位置(如 $C_{0,0}, C_{0,1}, C_{0,4}, C_{0,5} \dots$)。
结论:输出矩阵 C 的布局是高度碎片化的“交织马赛克(Checkerboard Pattern)”,这是为了在最后将结果写回寄存器堆时,最大化写入带宽并彻底消除写冲突。